目次
はじめに
Azure Kubernetes Service (AKS) 上の AWX で、ジョブやインベントリの同期を実行したとき、それにおおむね 4 分から 5 分程度以上の待ち時間 を要するタスクが含まれると、ジョブが失敗してしまうことがあるようです。
AWX の Issue として報告されている事象 で、もろもろ調べたり試したりした結果、なんやかんやで現時点では わりとダーティハック感の強いワークアラウンド しかなさそうな気配があったため、簡単に紹介です。
例えば、次のような シンプル極まりないプレイブック を動かすだけでも、AKS 上の AWX では 途中で失敗 してしまうことがあります。
---
- hosts: localhost
gather_facts: false
tasks:
- ansible.builtin.pause:
minutes: 10
追記: この問題は AWX 21.14.0 で解決されました。詳細は最下部で紹介しています。
状況の判断
この問題は、次の条件が揃うと発生する可能性があります。
- Azure Kubernetes Service(AKS)上に AWX を構築している
- Kubernetes 1.22.11(1.23.x、1.24.x でも再現報告あり)
- AWX 21.3.0(おそらくバージョンとは無関係に再現する)
- デフォルトの EE(
quay.io/ansible/awx-ee:latest)
- この AWX で、以下のいずれかを実行する
- 完了まで 4 分以上を要するタスクを含んだジョブ
- 完了まで 4 分以上を要するインベントリの同期
冒頭の例では、ansible.builtin.pause に 10 分かかるため、この条件に合致しています。
この問題が発生すると、ジョブは エラー のステータスで終了しますが、ジョブのログには特に何も記録されません。
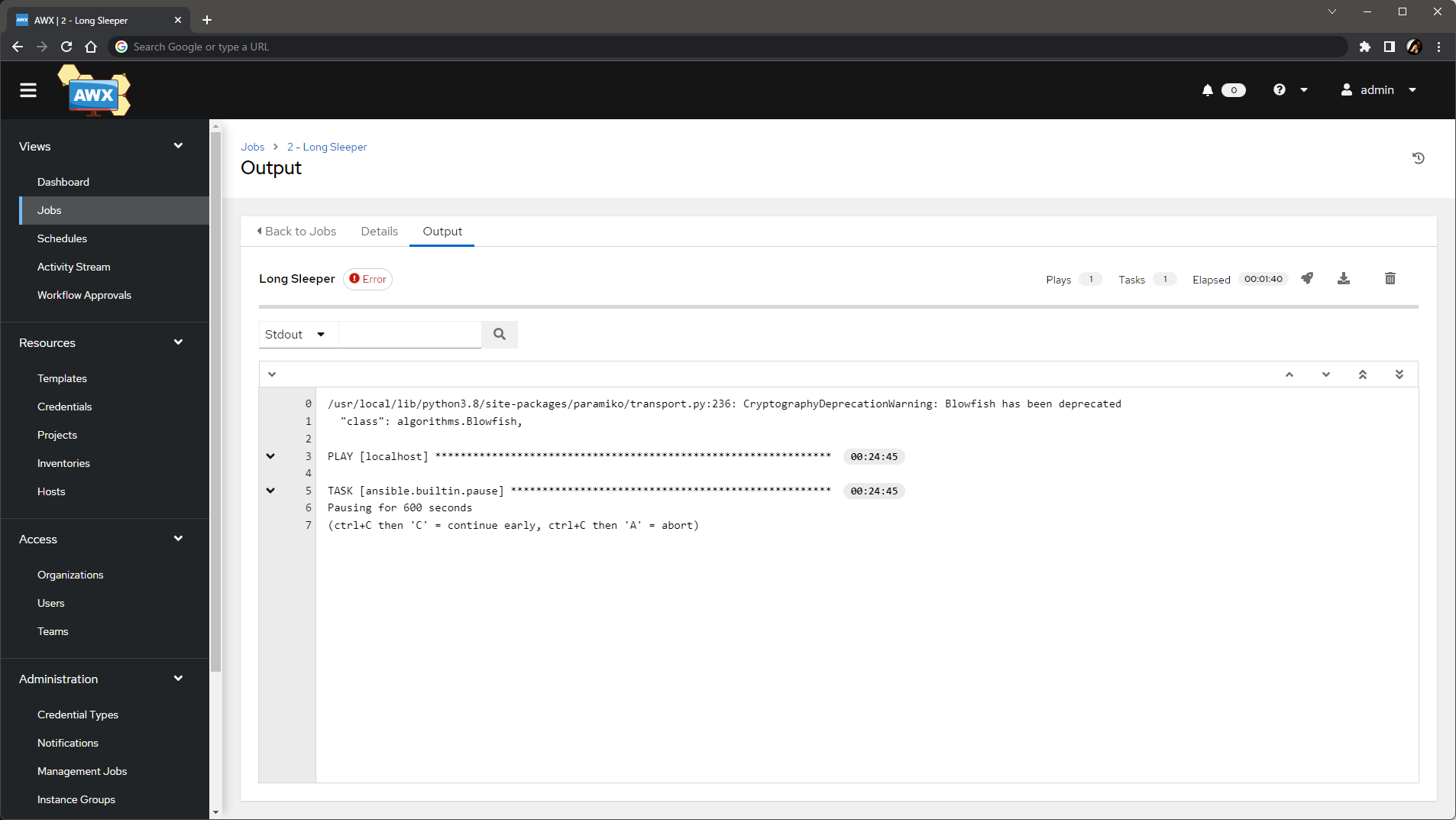
Details タブでは、エラーの理由として Job terminated due to error が記録されます。

原因と対応方針
原因
子の挙動は、AKS 内で Kubernetes の API サーバの TCP 通信 に 4 分の暗黙のアイドルタイムアウト があり、AWX と EE の間の通信が切断されてしまうことに起因しているようです。関連 Issue は #1052、#1755、#1877 あたりです。
AWX でジョブやインベントリの同期が実行されるとき、内部的にはおおまかには次のような処理が行われています。
- EE の Pod が作成される
- AWX の Pod の
awx-taskコンテナが、Kubernetes の API サーバに接続 して、EE の Pod のログのストリームを開く - EE の Pod でプレイブックが実行され、実行状況や結果が標準出力に逐次流される
- プレイブックの実行状況や結果が、Kubernetes の API サーバからのログストリーム経由で AWX の Pod の
awx-taskコンテナに届く
つまり、AWX の awx-task コンテナは、ジョブの実行開始から終了まで Kubernetes の API サーバとのログのストリーミング通信を開きっぱなし にします。その途中で EE のログに動きがない時間が 4 分以上続く と、AKS のアイドルタイムアウトの閾値を超えて TCP の接続が TCP RST パケットとともに切断されてしまい、ジョブが中断されてしまうということのようです。
対応方針
根本的には AKS 側でこのアイドルタイムアウトの時間を延ばせればよいのですが、前述の関連 Issue やドキュメントを見る限り、どうもユーザが触れる範囲のなにかではなさそうな雰囲気があります。AKS の仕様とアーキテクチャにはそこまで明るくないのであまり自信がないですが、LB の仕様に関するドキュメント はあるものの、API サーバの手前にいるのは Azure リソースとして見える Azure Standard Load Balancer(タイムアウトはデフォルトで 30 分)とは別物と思われ、手出しはできなそうです(この部分、識者からのつっこみに期待しています)。
そんなわけで、AKS 側での対処はいったんあきらめてユーザ側(クライアント側)でどうにかすることを考える必要がありますが、正攻法として考えられる TCP のキープアライブの明示的な利用 や TCP RST パケット受信後のストリームの再接続 は、現状の AWX(というか Ansible Runner、もっといえば Receptor)では、残念ながら実装されていません。
というわけで、現時点では どうにかして Kubernetes の API サーバと awx-task コンテナ間で定期的に通信を発生させる、すなわち EE の Pod にどうにかして定期的にログを吐かせる ことがワークアラウンドになりそうです。
対応
あからさまにダーティハック感がすごいので、ほかにもっとよい方法がある気がしてならないのですが、
- EE のエントリポイントのスクリプトを修正して
awx-taskが受け取っても安全に無視される文字列を- 無限ループで定期的に標準出力に吐かせる
なことを考えます。
エントリポイント用スクリプト
こんな感じの中身のファイルをファイル名 entrypoint で作ります。元のエントリポイントのスクリプトに、& 付きの while ループの 4 行(以下の例ではハイライトしている 48 行目以降)を足したものです。
コンテナ内のプロセスが増えることにはなりますが、本来の PID 1 とは無関係に動くため、コンテナ全体の動きには影響はありません。
#!/usr/bin/env bash
# In OpenShift, containers are run as a random high number uid
# that doesn't exist in /etc/passwd, but Ansible module utils
# require a named user. So if we're in OpenShift, we need to make
# one before Ansible runs.
if [[ (`id -u` -ge 500 || -z "${CURRENT_UID}") ]]; then
# Only needed for RHEL 8. Try deleting this conditional (not the code)
# sometime in the future. Seems to be fixed on Fedora 32
# If we are running in rootless podman, this file cannot be overwritten
ROOTLESS_MODE=$(cat /proc/self/uid_map | head -n1 | awk '{ print $2; }')
if [[ "$ROOTLESS_MODE" -eq "0" ]]; then
cat << EOF > /etc/passwd
root:x:0:0:root:/root:/bin/bash
runner:x:`id -u`:`id -g`:,,,:/home/runner:/bin/bash
EOF
fi
cat <<EOF > /etc/group
root:x:0:runner
runner:x:`id -g`:
EOF
fi
if [[ -n "${LAUNCHED_BY_RUNNER}" ]]; then
RUNNER_CALLBACKS=$(python3 -c "import ansible_runner.callbacks; print(ansible_runner.callbacks.__file__)")
# TODO: respect user callback settings via
# env ANSIBLE_CALLBACK_PLUGINS or ansible.cfg
export ANSIBLE_CALLBACK_PLUGINS="$(dirname $RUNNER_CALLBACKS)"
fi
if [[ -d ${AWX_ISOLATED_DATA_DIR} ]]; then
if output=$(ansible-galaxy collection list --format json 2> /dev/null); then
echo $output > ${AWX_ISOLATED_DATA_DIR}/collections.json
fi
ansible --version | head -n 1 > ${AWX_ISOLATED_DATA_DIR}/ansible_version.txt
fi
SCRIPT=/usr/local/bin/dumb-init
# NOTE(pabelanger): Downstream we install dumb-init from RPM.
if [ -f "/usr/bin/dumb-init" ]; then
SCRIPT=/usr/bin/dumb-init
fi
while /bin/true; do
sleep 120
echo '{"event": "FLUSH", "uuid": "keepalive", "counter": 0, "end_line": 0}' > /proc/1/fd/1
done &
exec $SCRIPT -- "${@}"
使う EE のイメージのバージョンによっては、元ネタにするべきエントリポイントのスクリプトも変わります。実際のイメージの中から kubectl cp で持ってくる(/usr/bin/entrypoint がそれです)か、ansible/ansible-runner リポジトリから適切なバージョンの元ネタのファイル を持ってくるとよいでしょう。
while ループでは、120 秒ごとに JSON 文字列を echo させています。echo 先は /proc/1/fd/1 で、つまり、コンテナのログとして扱われる、PID 1 の標準出力です。ここに吐いた文字列は、containerd から Kubernetes の API を経由して awx-task コンテナに伝わります。
詳細は割愛しますが、この JSON 文字列は Ansible Runner の Process フェイズ(AWX では awx-task 側)が受け取っても無害なように工夫してあります。逆に言えば、Process フェイズは受け取ったログの全行が所定のスキーマの JSON 文字列であることを暗黙に期待しているため、そのスキーマではない任意の文字列を送ってしまうと、うまく処理できずにジョブが失敗するか例外を吐くかで、期待した結果が得られません。
ConfigMap の作成
このスクリプトをもとに、EE が起動する Namespace に ConfigMap を作ります。
kubectl -n awx create configmap awx-runner-entrypoint --from-file=entrypoint
Container Group の作成
AWX 内で Container Group を作って、Custom pod spec として次の YAML 文字列をつっこみます。デフォルトのモノに volumes と volumeMounts を追加したものです(ベースにするべきデフォルトも AWX のバージョンで変わります)。
apiVersion: v1
kind: Pod
metadata:
namespace: awx
spec:
serviceAccountName: default
automountServiceAccountToken: false
containers:
- image: quay.io/ansible/awx-ee:latest
name: worker
args:
- ansible-runner
- worker
- '--private-data-dir=/runner'
resources:
requests:
cpu: 250m
memory: 100Mi
volumeMounts:
- mountPath: /usr/bin/entrypoint
name: awx-runner-entrypoint-volume
subPath: entrypoint
volumes:
- name: awx-runner-entrypoint-volume
configMap:
name: awx-runner-entrypoint
items:
- key: entrypoint
path: entrypoint
mode: 0775
これで、デフォルトのエントリポイントスクリプトが、前述の手順で作った ConfigMap 内の内容で置き換えられます。
Job Template の Instance Group の変更
Job Template で Instance Group として前述の手順で作成した Container Group を指定します。
結果
EE の Pod のログに、120 秒ごとにダミー文字列が吐かれるようになります。
$ kubectl -n awx logs -f automation-job-5-vr8v7
...
{"uuid": "5e8c23a8-8e7f-44c1-814c-f0ce1974eb02", "counter": 8, "stdout": "(ctrl+C then 'C' = continue early, ctrl+C then 'A' = abort)\r", "start_line": 7, "end_line": 8, "runner_ident": "5", "event": "verbose", "job_id": 5, "pid": 28, ...}
{"event": "FLUSH", "uuid": "keepalive", "counter": 0, "end_line": 0}
{"event": "FLUSH", "uuid": "keepalive", "counter": 0, "end_line": 0}
{"event": "FLUSH", "uuid": "keepalive", "counter": 0, "end_line": 0}
{"event": "FLUSH", "uuid": "keepalive", "counter": 0, "end_line": 0}
{"event": "FLUSH", "uuid": "keepalive", "counter": 0, "end_line": 0}
{"uuid": "9a4afe85-fa1f-4096-a2ab-897f8dcf89ef", "counter": 9, "stdout": "\u001b[0;32mok: [localhost]\u001b[0m", "start_line": 8, "end_line": 9, "runner_ident": "5", "event": "runner_on_ok", "job_id": 5, "pid": 22, ...}
...
この文字列は Kubernetes の API サーバを通じて awx-task にも届くため、awx-task が開いたストリームには定期的に通信が発生することになり、タイムアウトを迎えることがなくなります。
なお、標準出力のロックは Ansible Runner の awx_display コールバックプラグインの中でハンドリングされているようで、ざっとコードや実機で確認した範囲では、Ansible Runner の本来の出力とエントリポイント中の echo が衝突してログの JSON 文字列が破壊されるような事故は起きないように見えています(たぶん)。
まとめ
AKS 上に AWX をデプロイして使うときのダーティハックを紹介しました。
もっとよい方法がありそう(あるいはユーザ側でなく Ansible Runner 側か Receptor 側で解決されるべき)なので、何か思いついたら(または実装で解決できたら、もしくはされたら)更新します。
追記: AWX 21.14.0 での恒久対策
AWX の 21.14.0 で、本問題への恒久対策が実装されました。より具体的には、Ansible Runner の 2.3.2 でキープアライブメッセージを定期的に送信する機能が実装され、AWX の 21.14.0 でその機能を使えるようになった形です。
以下を充足することで、この機能を有効化できます。
- AWX を 21.14.0 以降にアップグレードする
- ジョブ用の EE イメージとして、最新の
quay.io/ansible/awx-ee:latest、またはquay.io/ansible/awx-ee:21.14.0以降を利用する - AWX の
Settings>Job settingsのK8S Ansible Runner Keep-Alive Message Intervalで、キープアライブメッセージの送信間隔を 1 以上に設定する