はじめに
Dify の今年の目玉機能のひとつ、ナレッジパイプライン(Knowledge Pipeline)が、昨日、Dify の 2.0.0 のベータ版(beta.1)の機能のひとつとしてリリースされました。
この機能、ベータ版の公開前から勝手に興味をもって個人的に実際に動かして触ったりバグをちょこっと直したり機能をちょこっと足したりしていたので、ベータ版の公開に合わせて、簡単に紹介します。
ただし、以下の点、ご了承ください。
- ベータ版より前の開発途中のソースコードを手掛かりに、公式のドキュメントなどが何もない段階で、自分の体験や理解・解釈に基づいてまとめたものです
- 開発途中ならではのバグにより実際には動かせなかった部分を推測で補っているところもあります
- したがって、本エントリの内容は正式なリリースの内容とは一致しない可能性があります
目次
概要: ナレッジを作るためのワークフローのようなもの
ナレッジパイプライン は、ぼくの理解では、ナレッジを作るためのワークフロー(のようなもの)です。
とても簡単にいうと、以下のようなことを ワークフロー形式でツールや分岐も駆使しながら自分で好きなように組める ということです。
- ナレッジの元になるデータをどこからとってきて
- そこから情報をどのように抽出したり整形したりして
- どのようにチャンクにわけて
- ベクトル DB にどのように埋め込むか
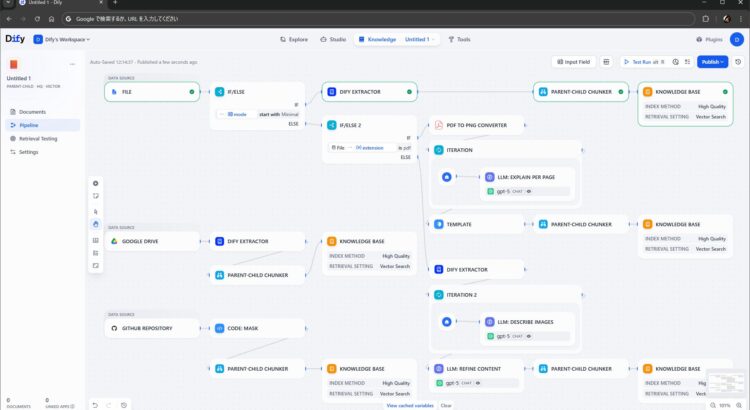
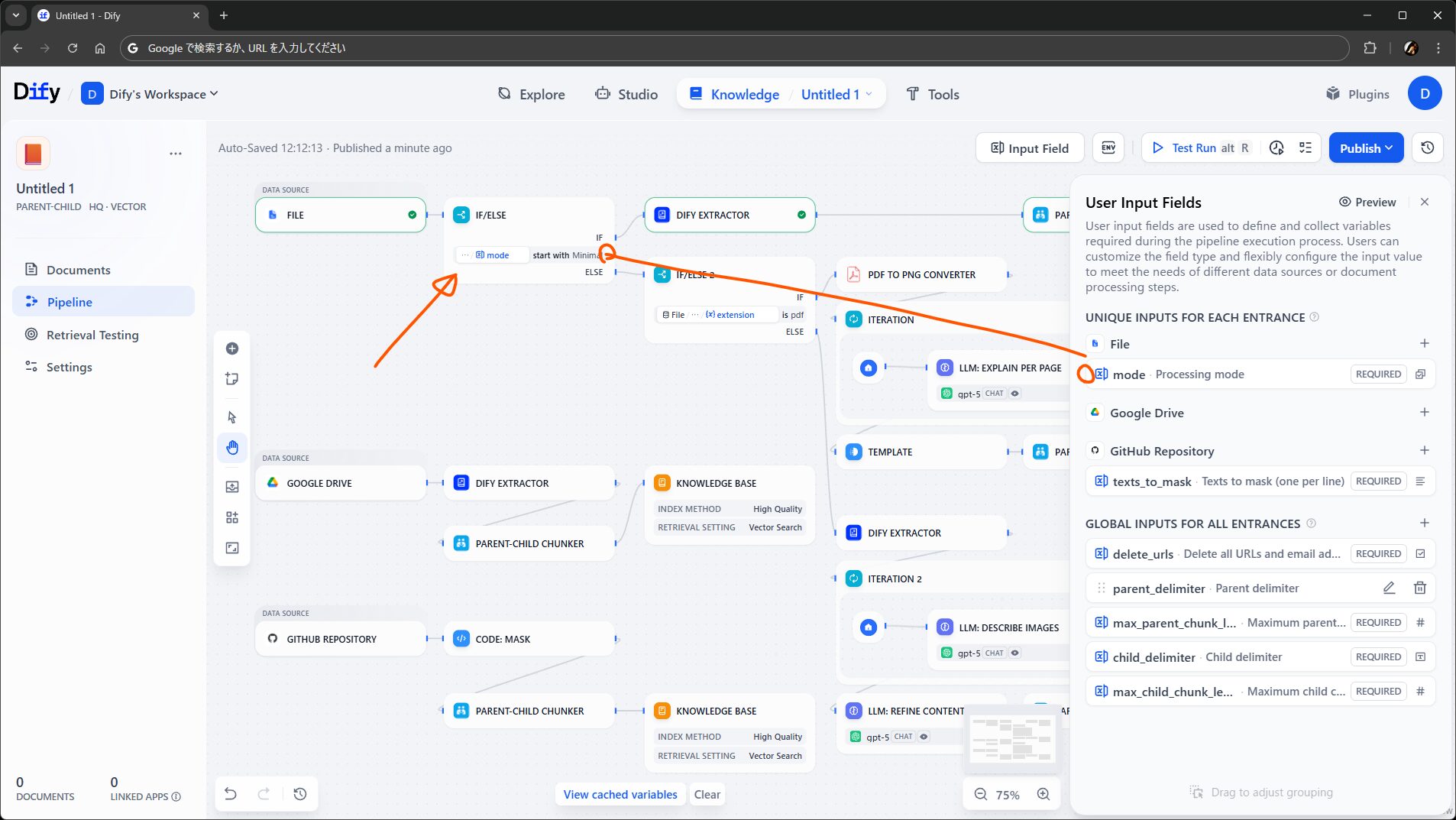
実際の画面はこんな感じです。ワークフローやチャットフローを作ったことがある方々にとってはとても見慣れた雰囲気のやつです。詳細は後述しますが、ナレッジごと にこの編集画面を操作できるようになります。
極端な例として、見た目(?)重視で作ったので動きませんが、アプリのワークフローっぽく条件分岐やループや LLM ノードやツールを使った複雑なものも組めます。
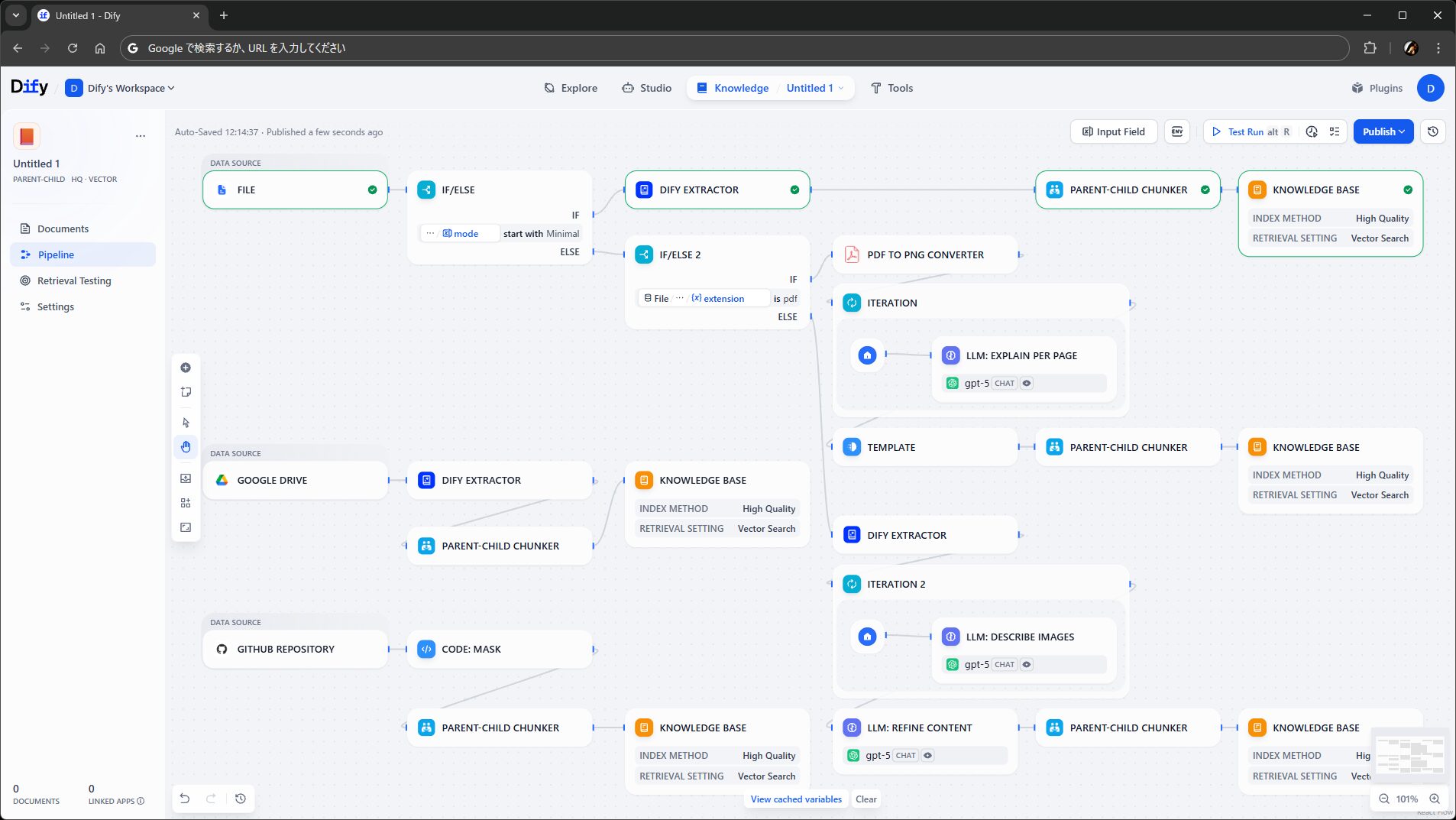
ウォークスルー: 実際の作り方と使い方
踏み込んだ説明の前に、ナレッジパイプラインの作り方と使い方を、スクリーンショットで簡単に紹介します。こういう見た目でこういう操作感のモノができる、という感触をふんわり把握いただけると、後述する細かい説明もたぶんわかりやすくなる…… と思います。
繰り返しますが、画面は開発中のものなので、リリース版とはおそらく少し異なります。流れは一緒のはずです。
ナレッジの新規作成
パイプラインはナレッジごとに作るものなので、まずはナレッジを作成します。
Knowledge ページに進むと、今まで通りの Create Knowledge に加えて、新しく Create from Knowledge Pipeline があります。今まで通りのナレッジで充分な場合は、前者を選択すればパイプラインのないナレッジが引き続き作れます。今回は後者です。
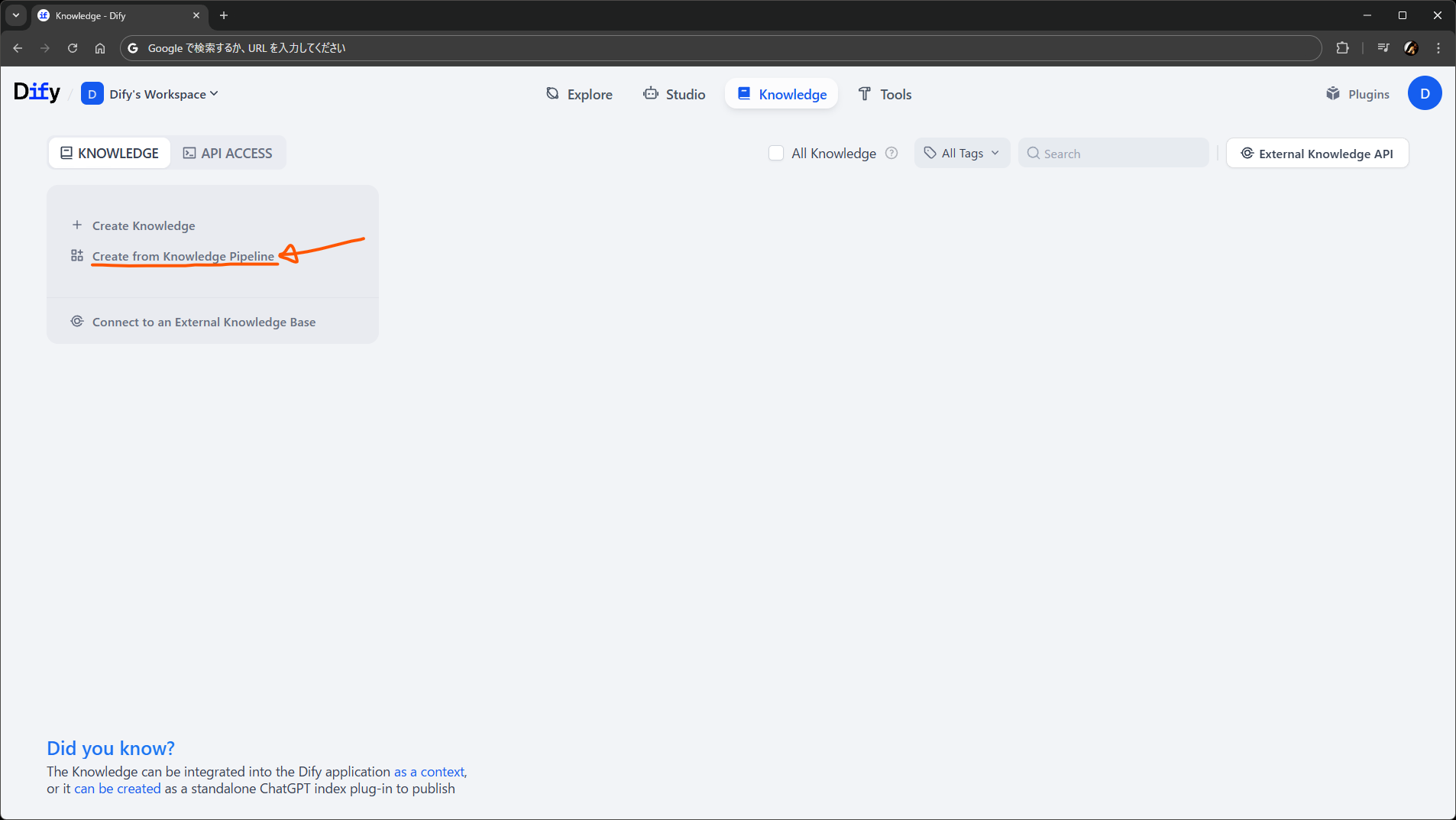
Create from Knowledge Pipeline を選択して進むと、パイプラインのテンプレートを選ぶ画面に進みます。……が、Blank knowledge pipeline 以外はなにもありません。
開発中だからないのか、あるいはコミュニティ版はこういうものなのか、どちらかわかりませんが、実装上はテンプレートを取得する API のエンドポイントは用意されていますし、Enterprise 版ではカスタムテンプレートが作れそうです。コミュニティ向けにも何か公開されるのでしょうか。
さて、おとなしく Blank knowledge pipeline を選んで進むと、パイプラインの作成画面に入ります(初期状態がリリース版と違いますが、やることは一緒です)。
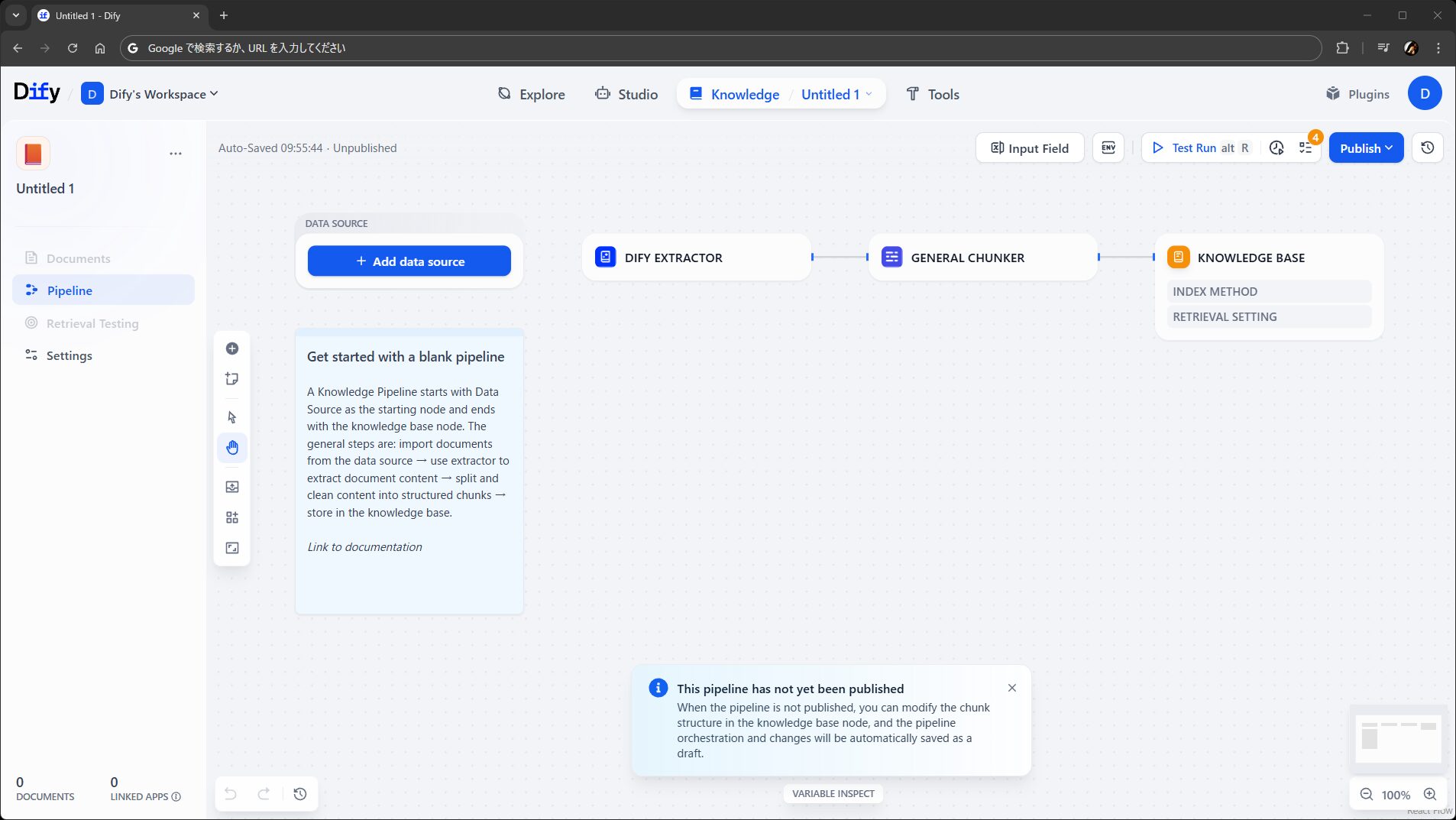
パイプラインの編集
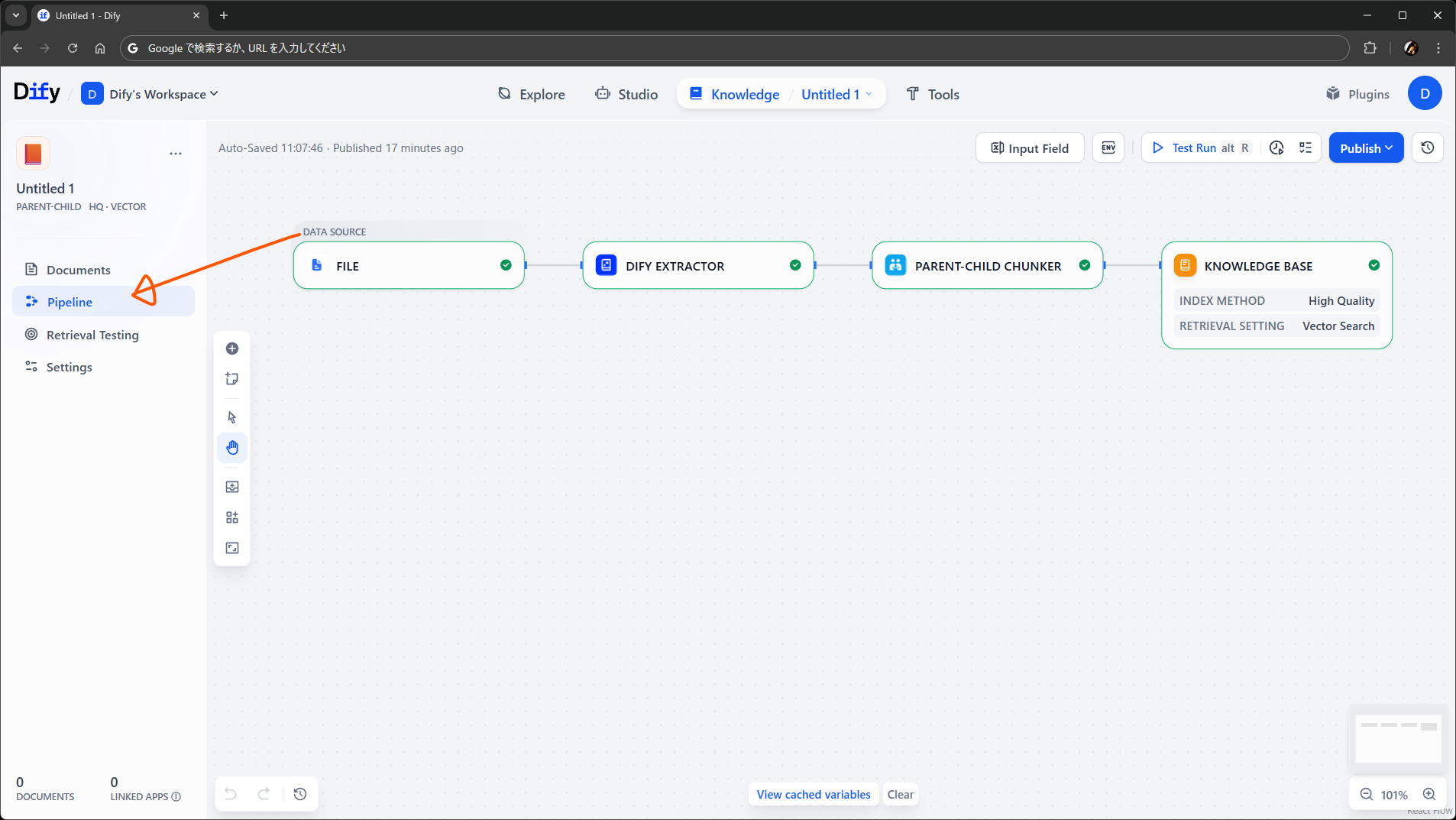
Add data source から、ナレッジのもとになるデータを取得するノードを追加します。ワークフローでいう開始ノードみたいなものですね。見た目で察した方も多いと思いますが、データソースノードの種類もプラグインで増やせます。
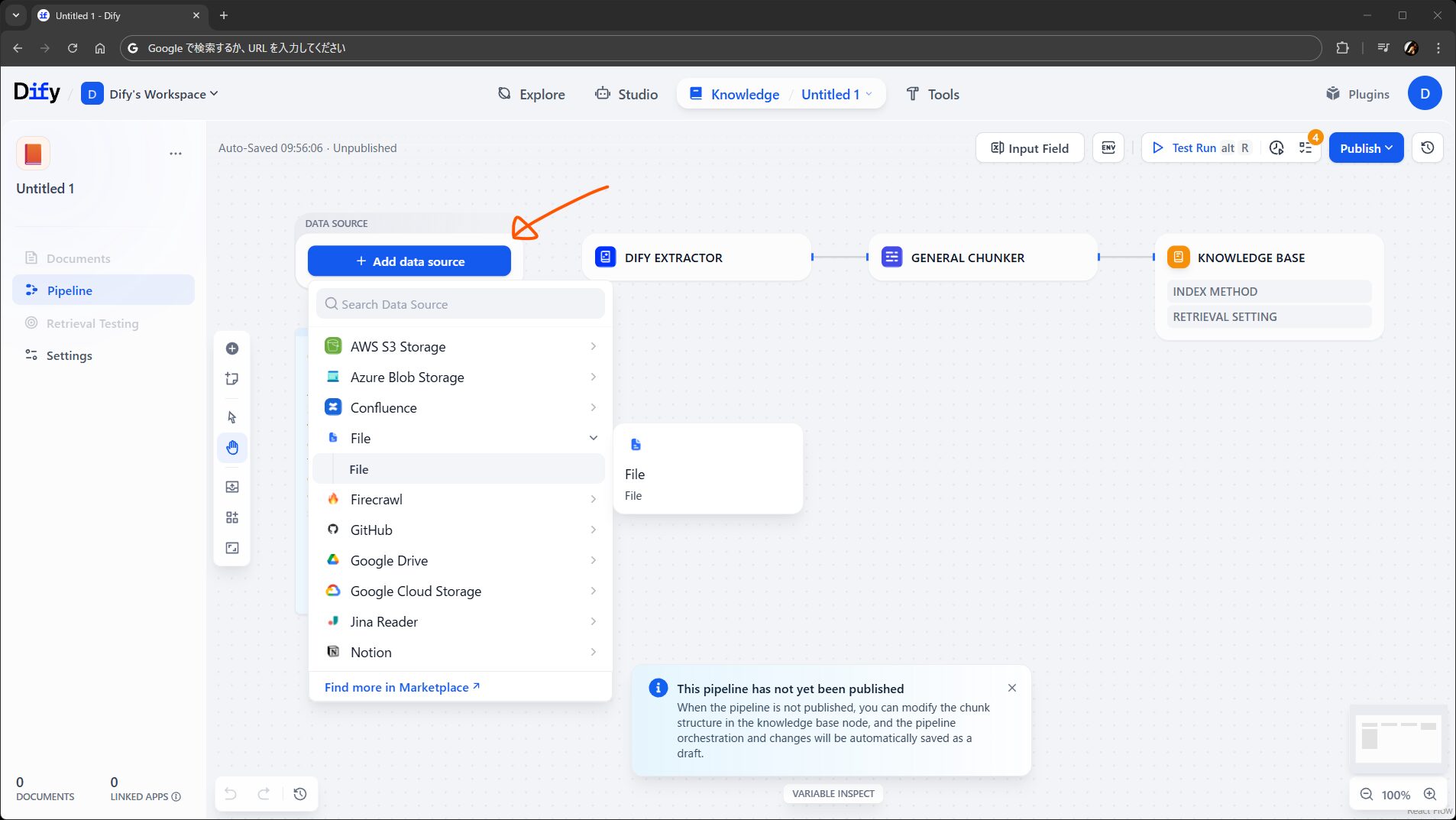
とりあえず、従来通りのファイルアップロードを受け付けるようにします。
File データソースを配置します。受け入れる拡張子を設定できますが、デフォルトで進めます。出力は File 型のオブジェクトです。次の Dify Extractor に接続します。
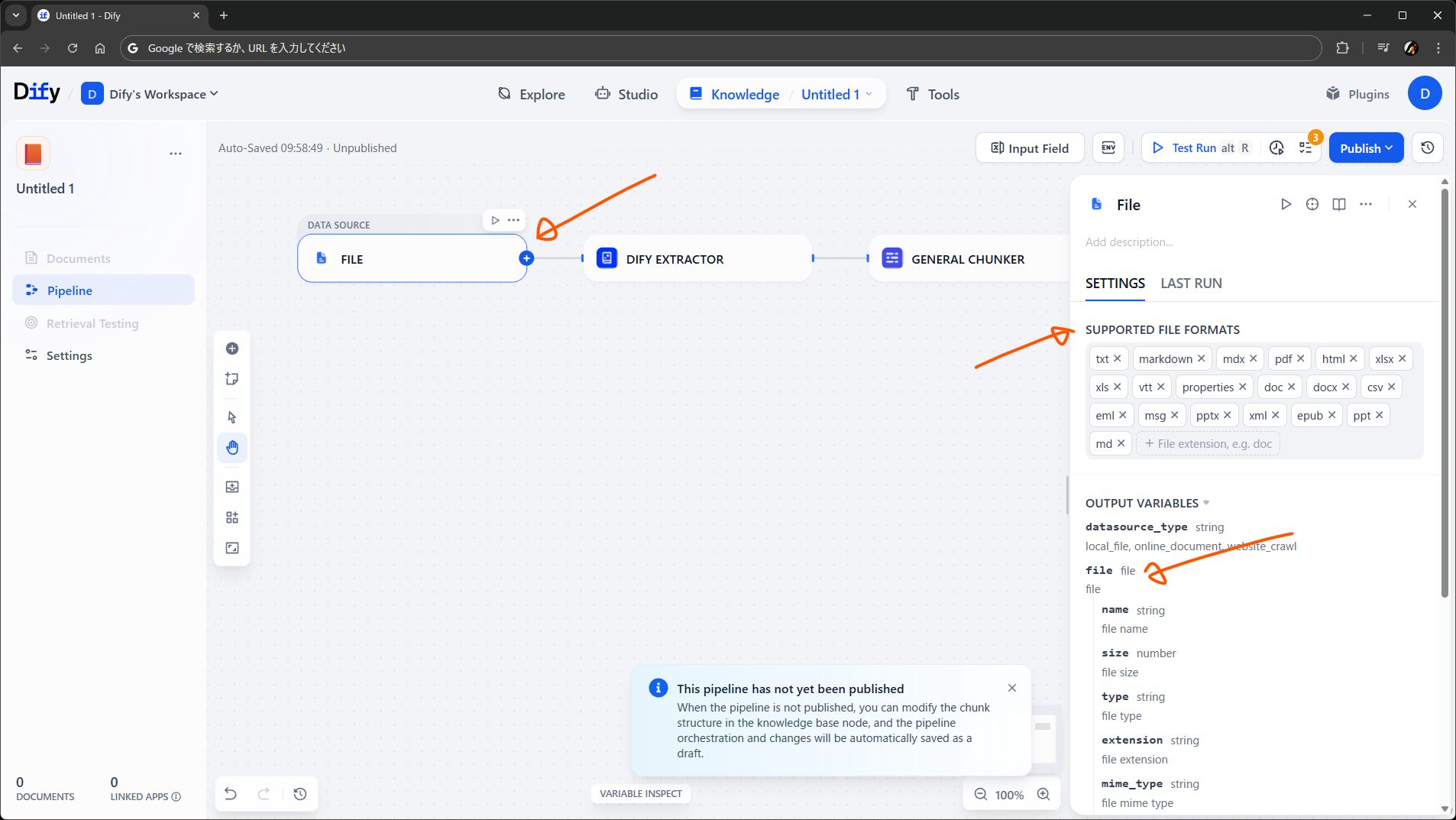
次の Dify Extractor は、ファイルからテキストと画像を抽出するノードで、従来のナレッジの裏側で動いていた機能がプラグインとして移植されたもの(にちょっと機能が増えたもの)です。
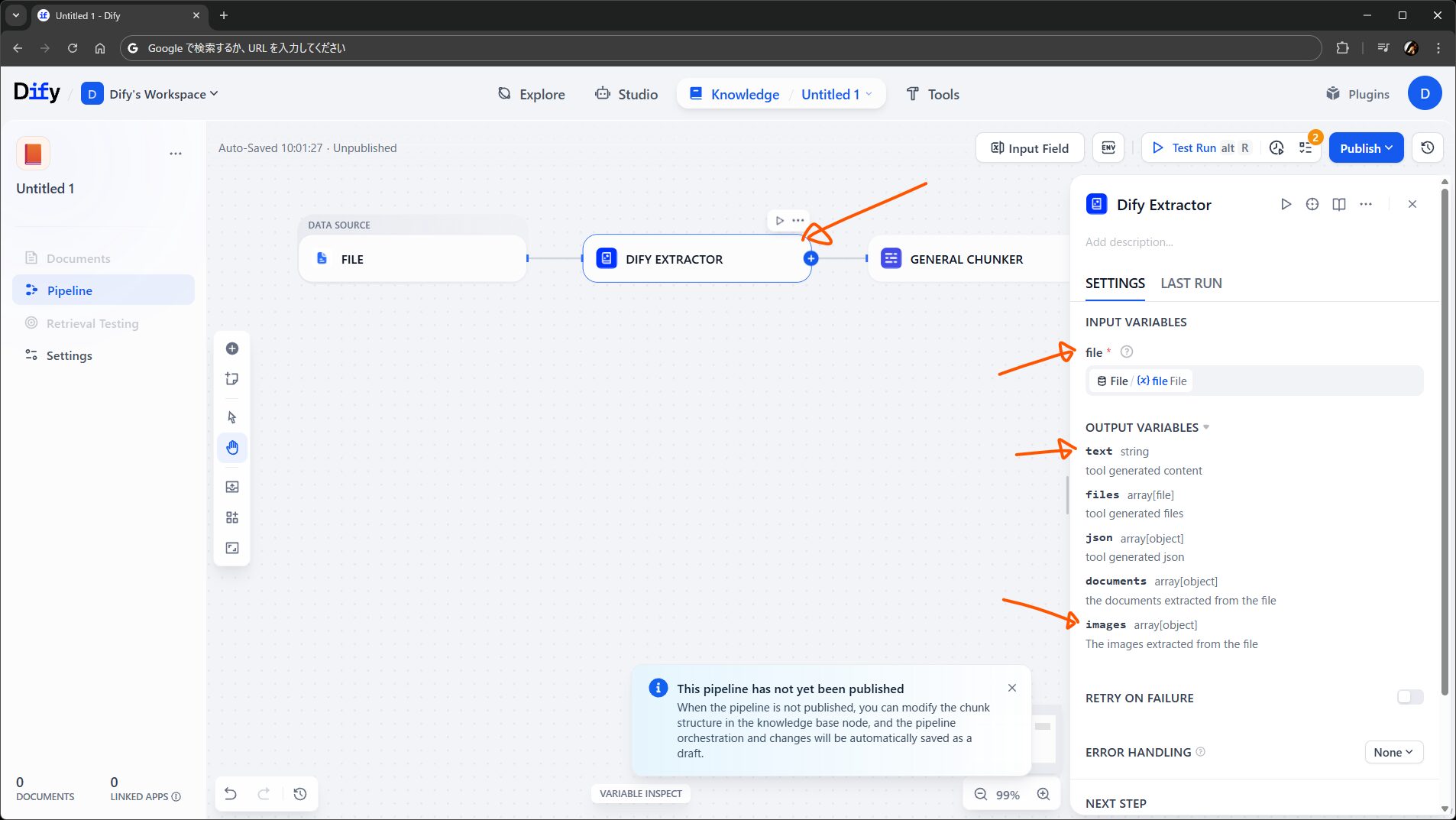
ワークフロー向けの Doc Extractor と違って、ファイル内の画像群が images として別に出力されるようです。この出力を、例えば LLM ノードの Vision に渡して説明させたテキストそれ自体をナレッジに入れる、など応用もできそうですね。
今回はいったん入力に File ノードからの出力を渡すだけにしておきます。
続けて General Chunker ノードです。従来のナレッジでもチャンキングの方法を選ぶ画面がありましたが、アレに相当する部分です。
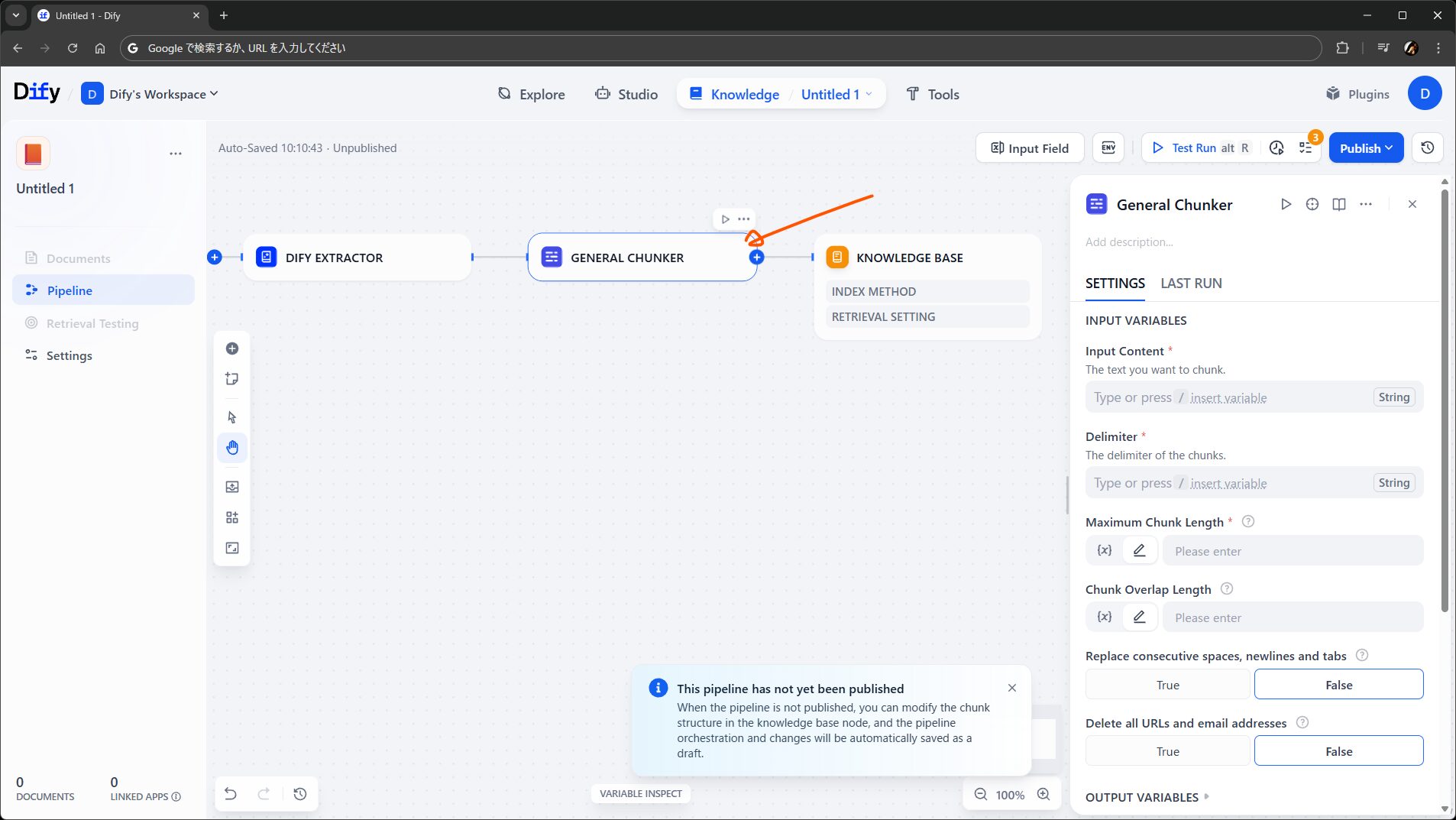
このノードは、名前の通り汎用モード用のチャンクを作る役割を持ちます。今回は親子モードを使いたいので、Parent-child Chunker に置き換えました。入力は Dify Extractor ノードの出力を渡します。
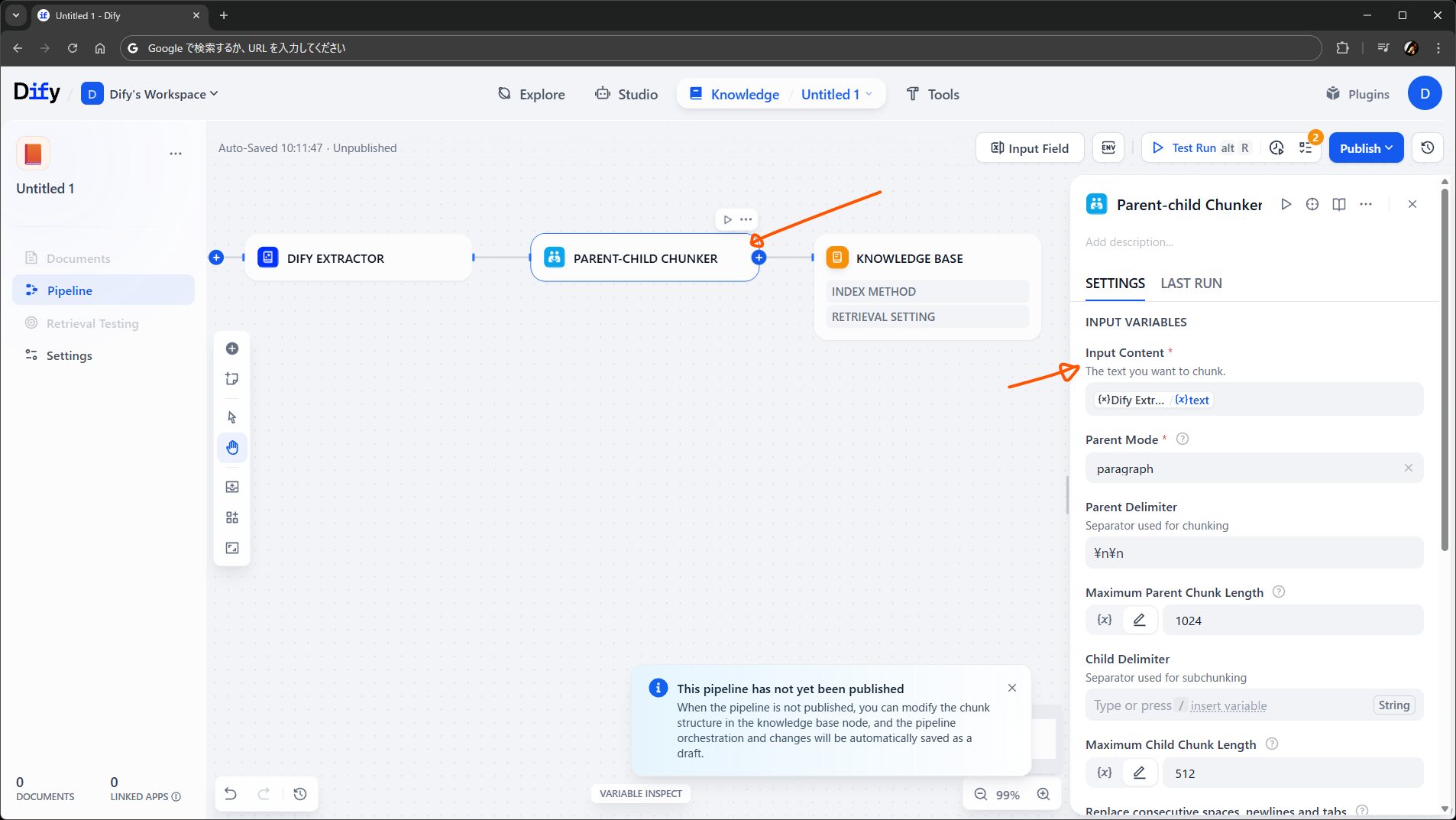
最後が Knowledge Base ノードです。ワークフローでいう終了ノードみたいなものです。今回は前のノードから親子型のチャンクを流し込みたいので、Chunk Structure を Parent-child にして入力を設定します。
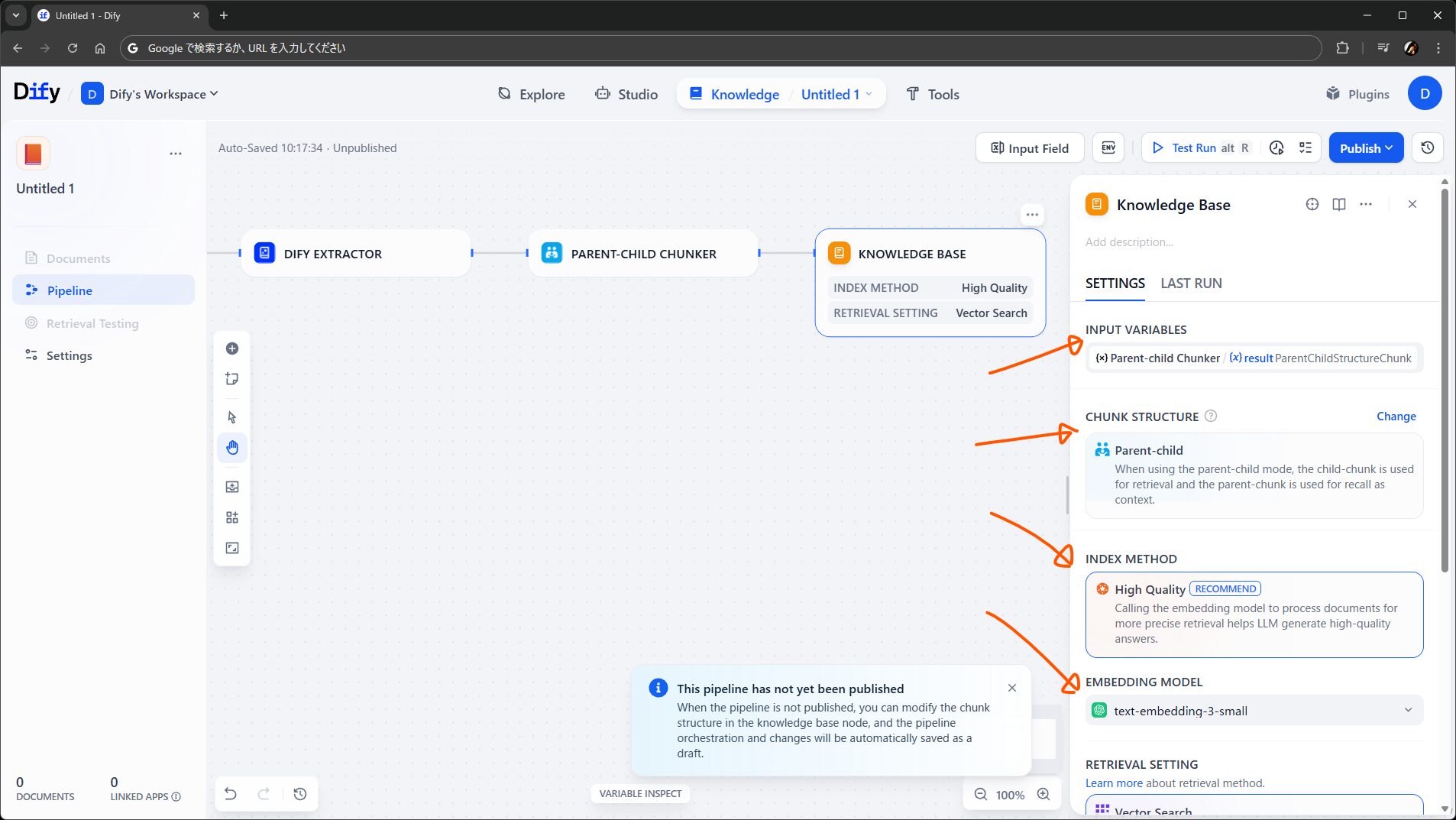
ほか、インデキシング方法や埋め込みに使うモデル、検索方法を指定します。
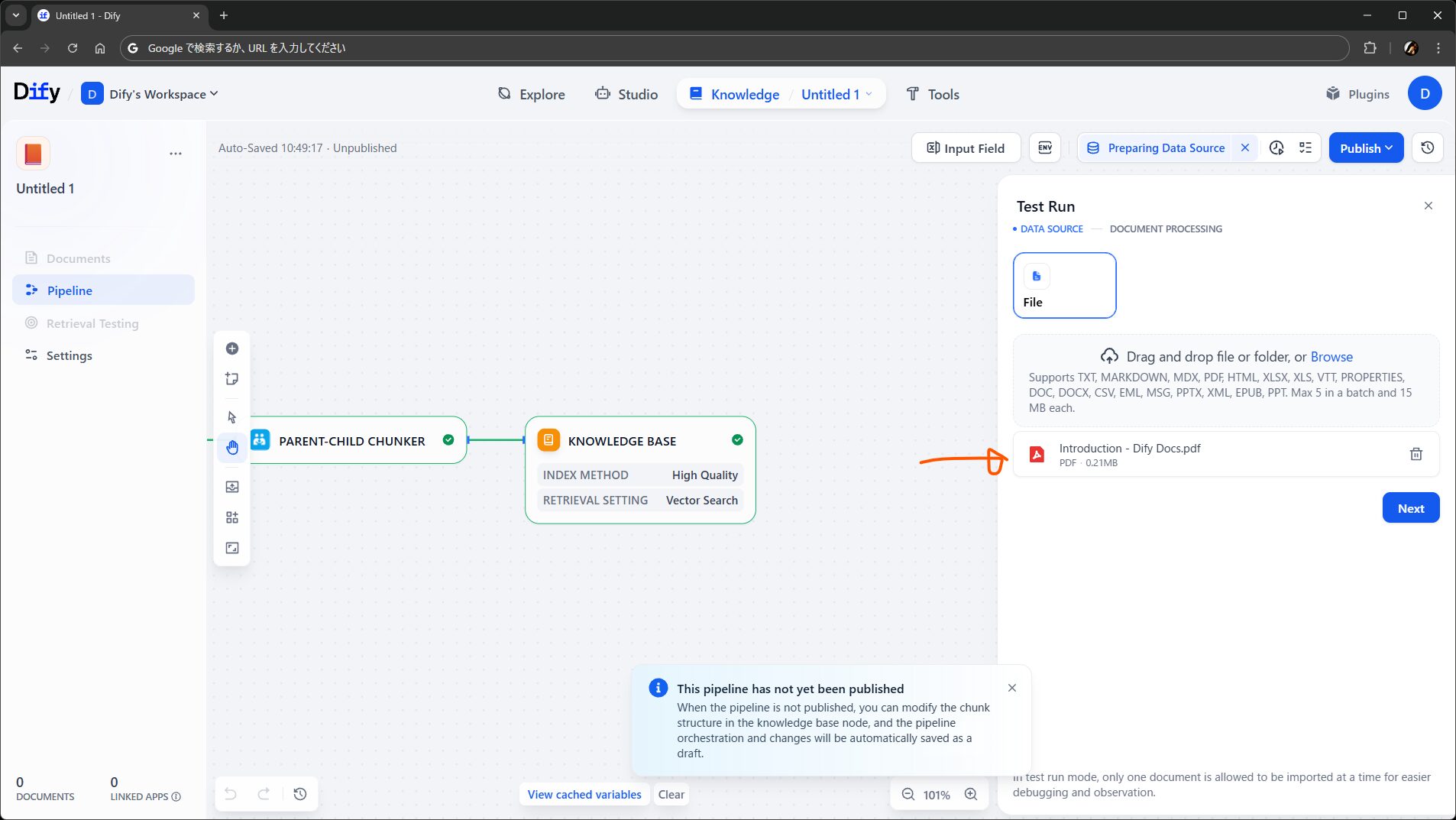
できたら Test Run しましょう。ファイルをアップロードして処理を進め、いい感じだったら Publish して完成です。
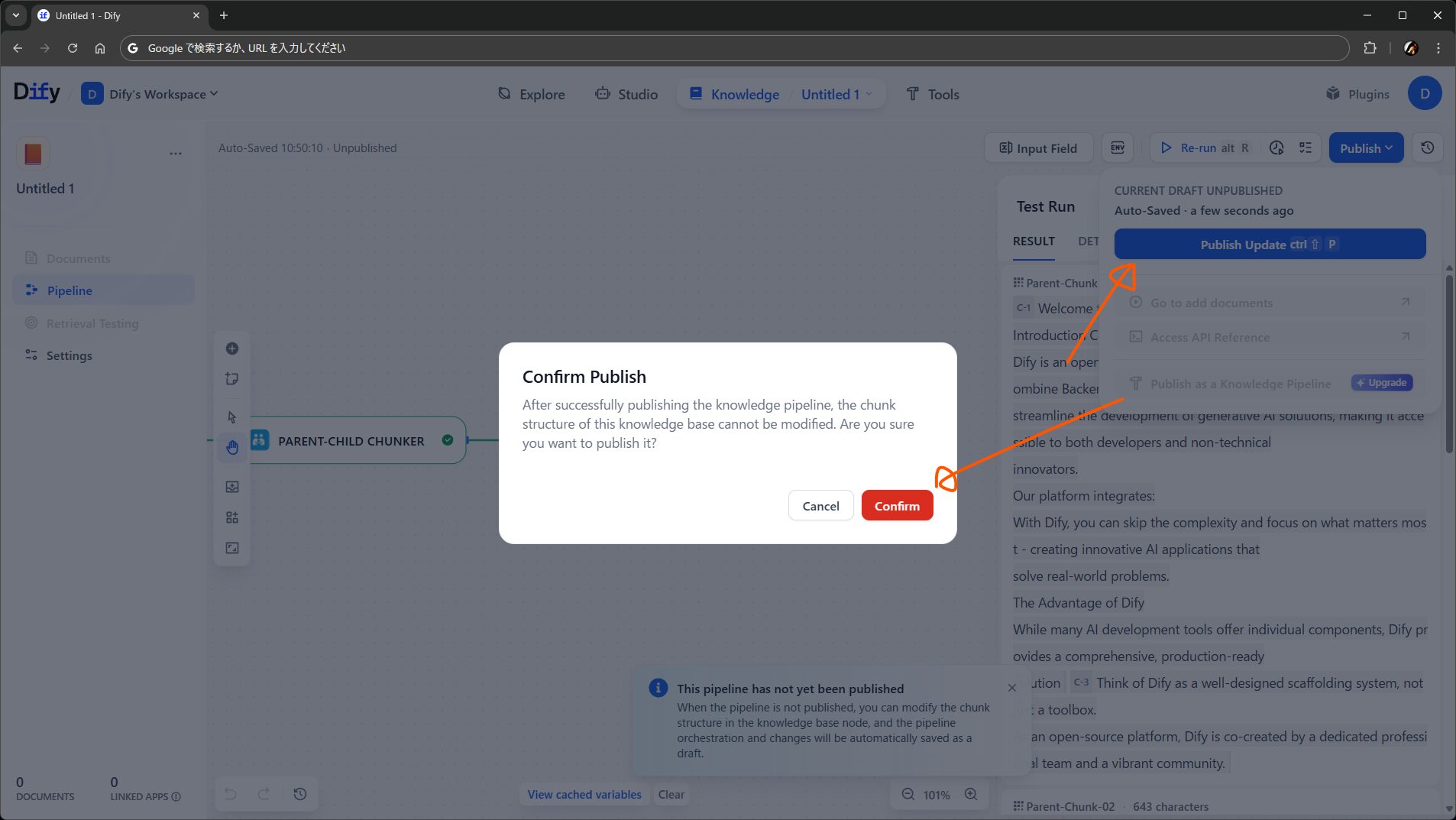
余談ですが、Publish as a Knowledge Pipeline というメニュが見えます。Enterprise 向けの、パイプラインをテンプレート化できる機能のようです。
ドキュメントの追加
パイプラインを保存できたら、以降はナレッジの Documents メニュからドキュメントを追加できます。
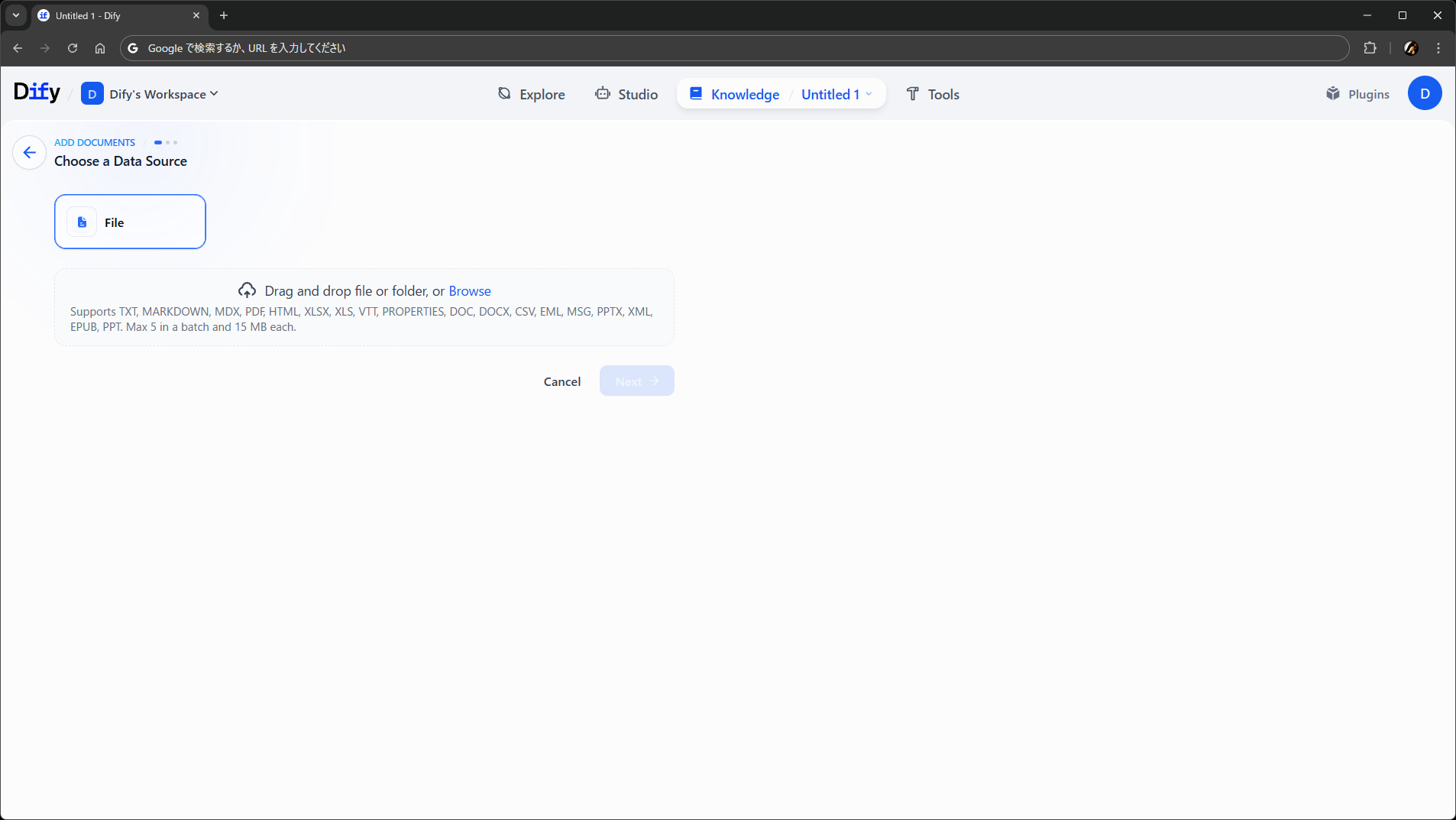
Chunk Settings は、今回のパイプラインだと何もありません。後述しますが、実行時にユーザからの入力を受け付けるように構成すると、ここに表示されるようになります。
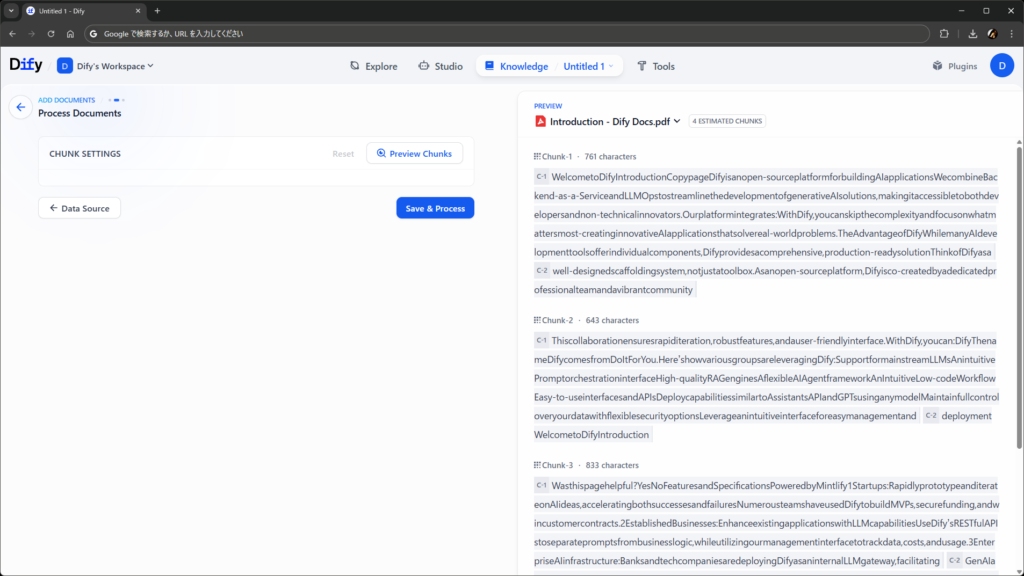
このあとの埋め込み処理や、完了後のドキュメントの見え方は、今までとさほど変わりません。
パイプラインの編集
作成済みのパイプラインは、左ペインの Pipeline メニュから編集できます。
応用: 複数のデータソースの利用
ひとつのパイプラインに、データソースノードは複数配置できます。
例えば、File の横に Google Drive ノードを追加して、認証を済ませてから Run this step をすると、Google Drive 上のファイルが一覧されます。ナレッジに足したいファイルが選べそうな雰囲気です。
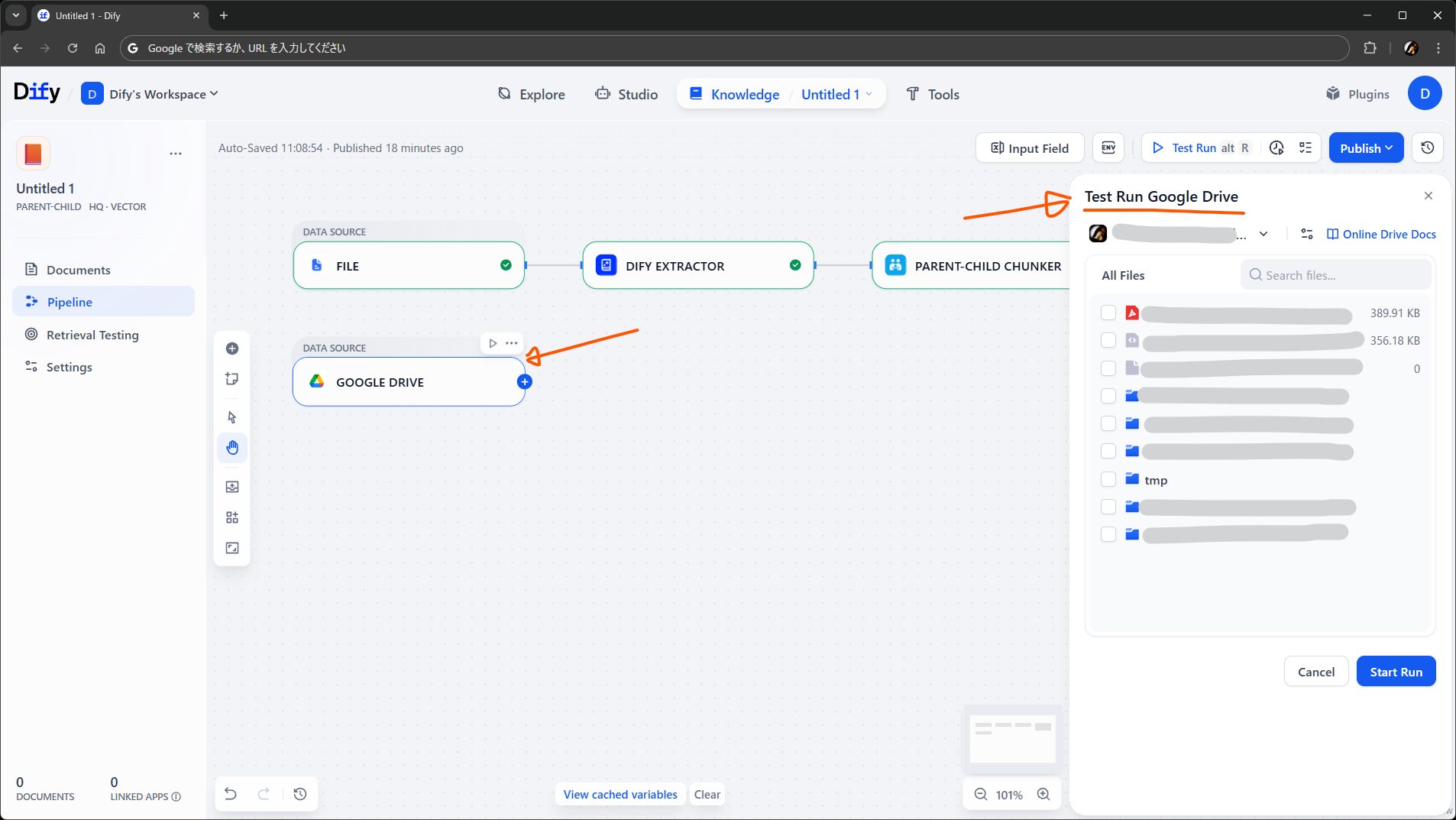
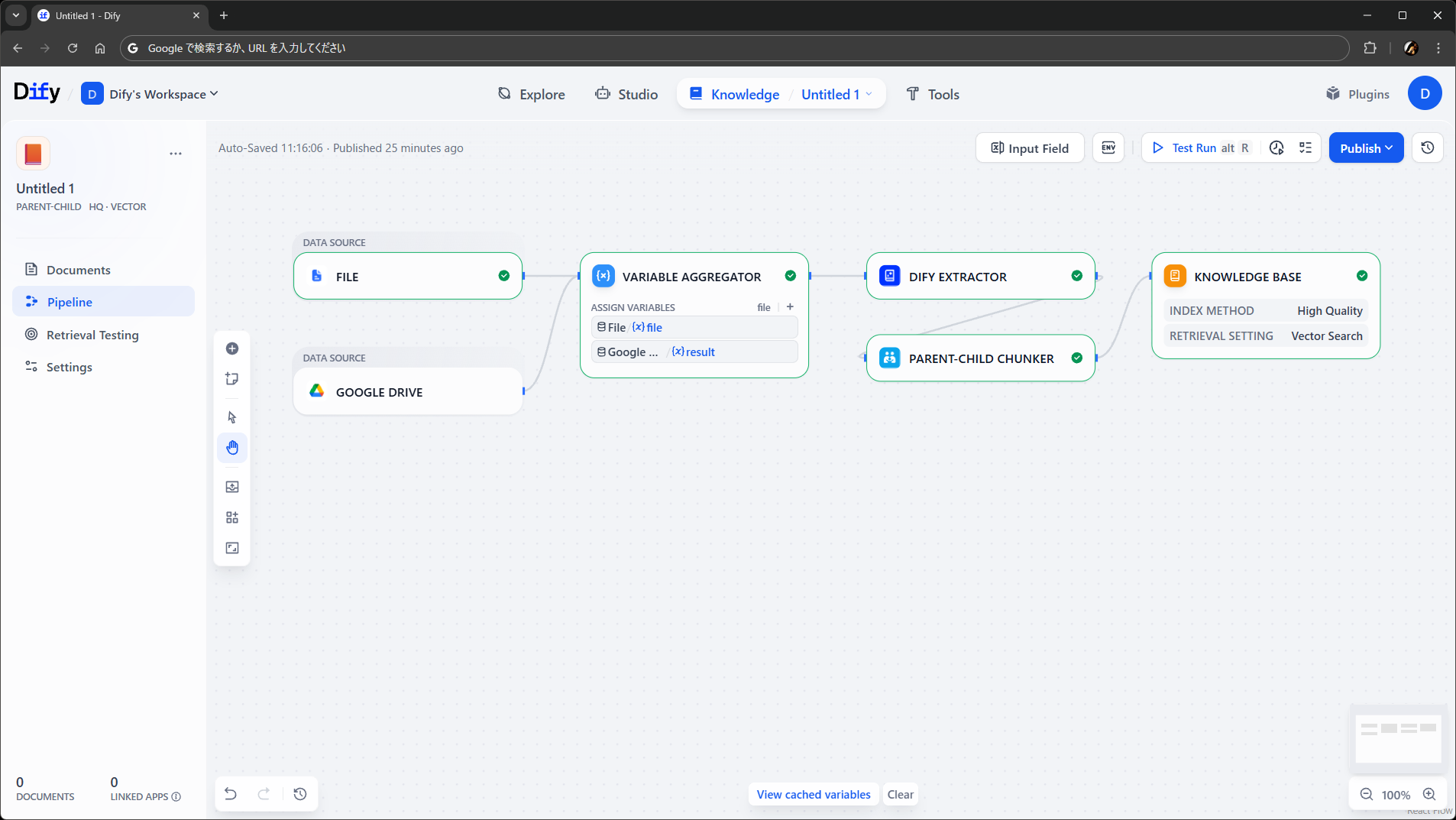
あとは好きなように後ろにノードをつなげて、最後の Knowledge Base ノードまで流れるようにすればヨシです。とても単純に組むならこんな感じでしょうか。ソースによってその後の処理を変えたい場合は、素直に Knowledge Base ノードまでの流れを 2 本並べる形でもよさそうです。
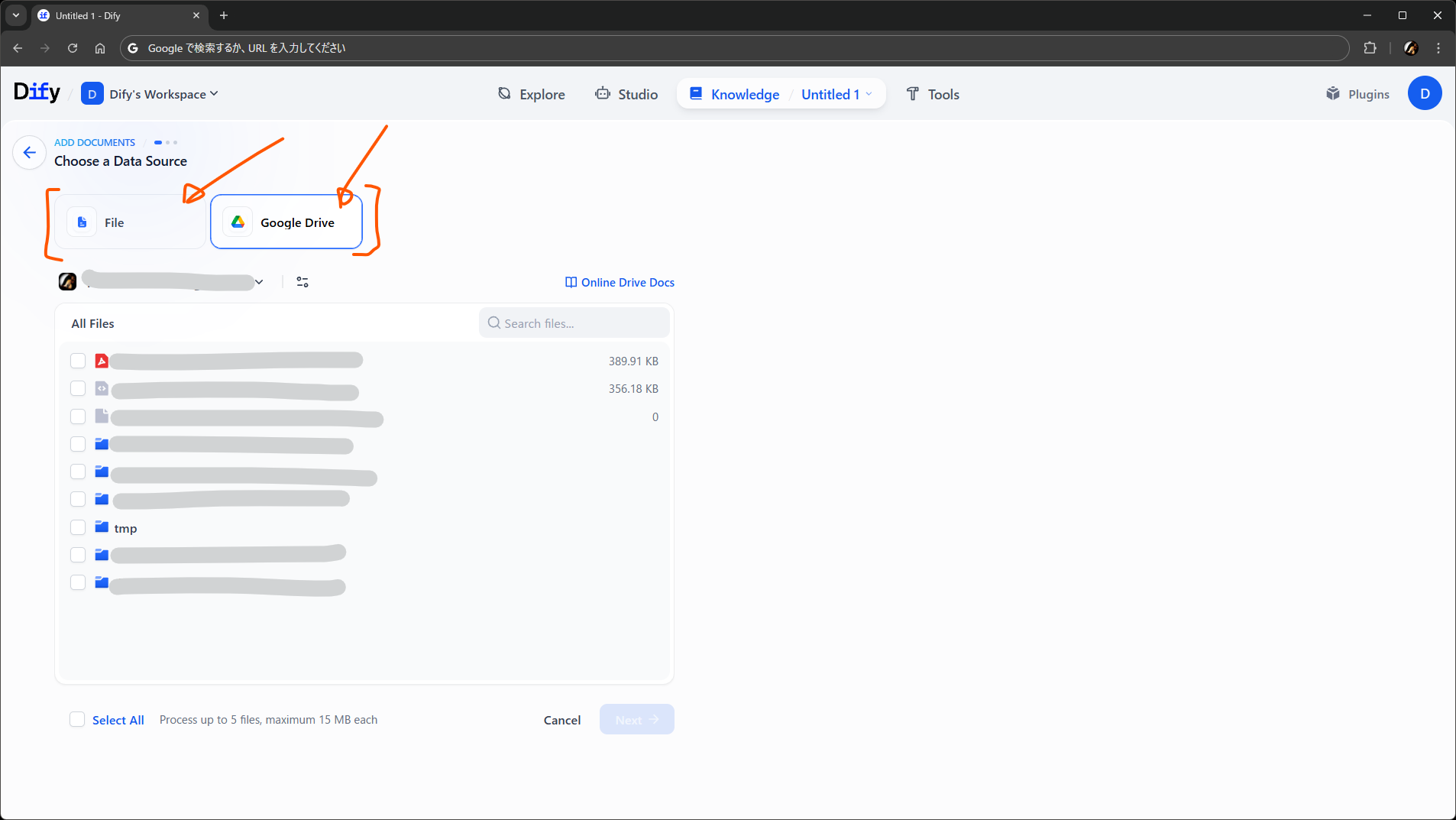
このようにデータソースを複数配置すると、ユーザ目線では、ドキュメントを追加する画面でソースの種類を選べるようになります。Google Drive の場合は、ナレッジに追加するファイルを選択して先に進む形です。
応用: ユーザ入力フィールド
パイプライン側で設定をすれば、ドキュメントを追加する画面に、ユーザからの入力を受け付ける欄を追加できます。ワークフローでいう開始ノードの変数みたいなもので、従来のナレッジの詳細設定画面のように使えます。
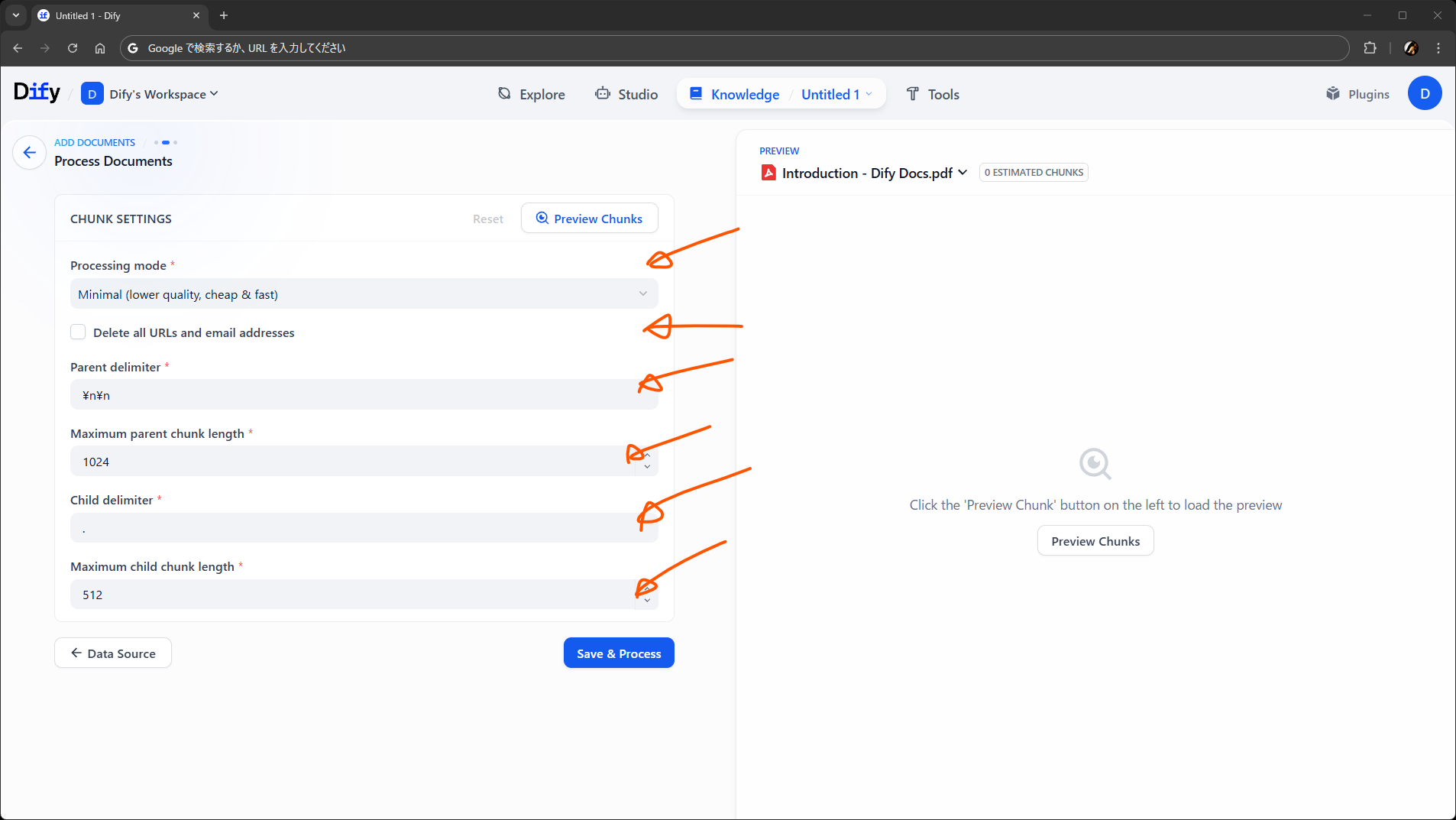
ユーザ入力フィールドの設定場所は、パイプラインの編集画面の上部の Input Field です。特定のデータソース向けのフィールドと全データソースで共通のフィールドを設定でき、値はパイプライン中で参照できます。
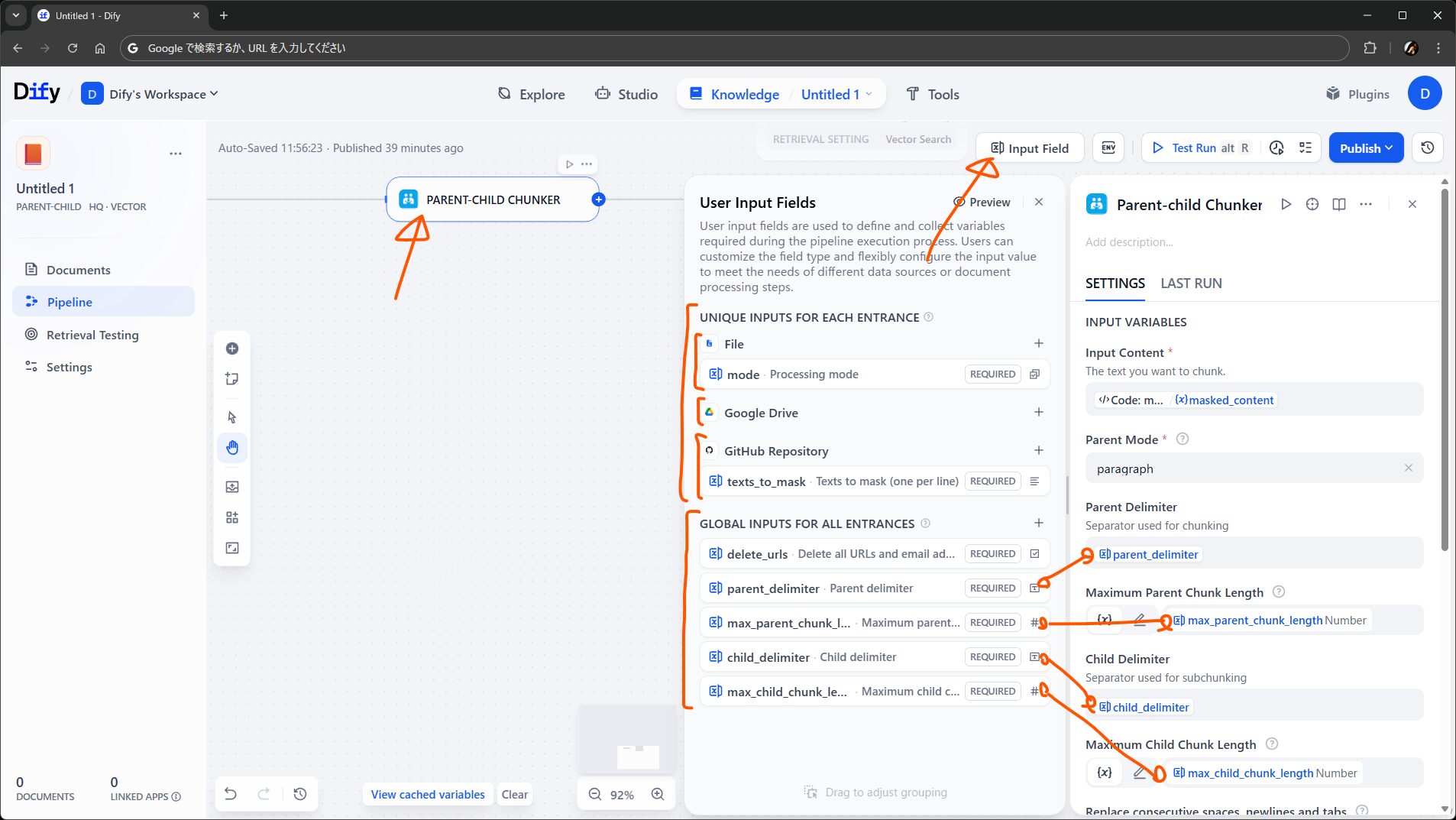
上の画面のように、チャンキングの際のデリミタやチャンク長さをユーザが指定できるようにしたり、ユーザの選択に応じて IF/ELSE ノードで後続の処理を切り替える目的などで利用できます。
もうちょっと詳しく: ステップごとの考え方
ナレッジパイプラインは、ここまでで紹介したように、従来のアプリのワークフローのように、データソースノードを起点にさまざまなノードやツールを自由に組み合わせて作成できます。
もう一歩踏み込んだ理解をするには、ナレッジパイプラインを大きく 次の 4 つのステップ に分けて考えるとよさそうです(勝手に分類して命名しただけなので、正式な何かがあったらごめんなさい)。
- 1️⃣ データソース
- ナレッジのもとになるデータを何らかのソースから取得するステップ
- 例: ユーザからのアップロード(従来と同じ)
- 例: 外部のオブジェクトストレージやオンラインストレージからのダウンロード
- 例: 外部のコラボレーションツールの参照
- 例: Web ページの取得
- ナレッジのもとになるデータを何らかのソースから取得するステップ
- 2️⃣ 抽出・クレンジング
- 前のステップで取得したファイルやコンテンツから、テキストを抽出したり、整形したり、クレンジングしたりするステップ(いわゆる ETL に相当)
- 例: いつも通りのテキスト抽出(従来と同じ)
- 例: Unstructured や MinerU などサードパーティの仕組み
- 前のステップで取得したファイルやコンテンツから、テキストを抽出したり、整形したり、クレンジングしたりするステップ(いわゆる ETL に相当)
- 3️⃣ チャンク
- 前のステップでできた文字列をチャンクに分けるステップ
- 例: 汎用モード(従来と同じ)
- 例: 親子モード
- 前のステップでできた文字列をチャンクに分けるステップ
- 4️⃣ ナレッジベース
- チャンクを保存するステップ
以下、各ステップを簡単に紹介します。
データソース: ナレッジのもとになるデータを取得する
ナレッジのもとになるデータを、どこかからどうにかして取ってくるステップです。
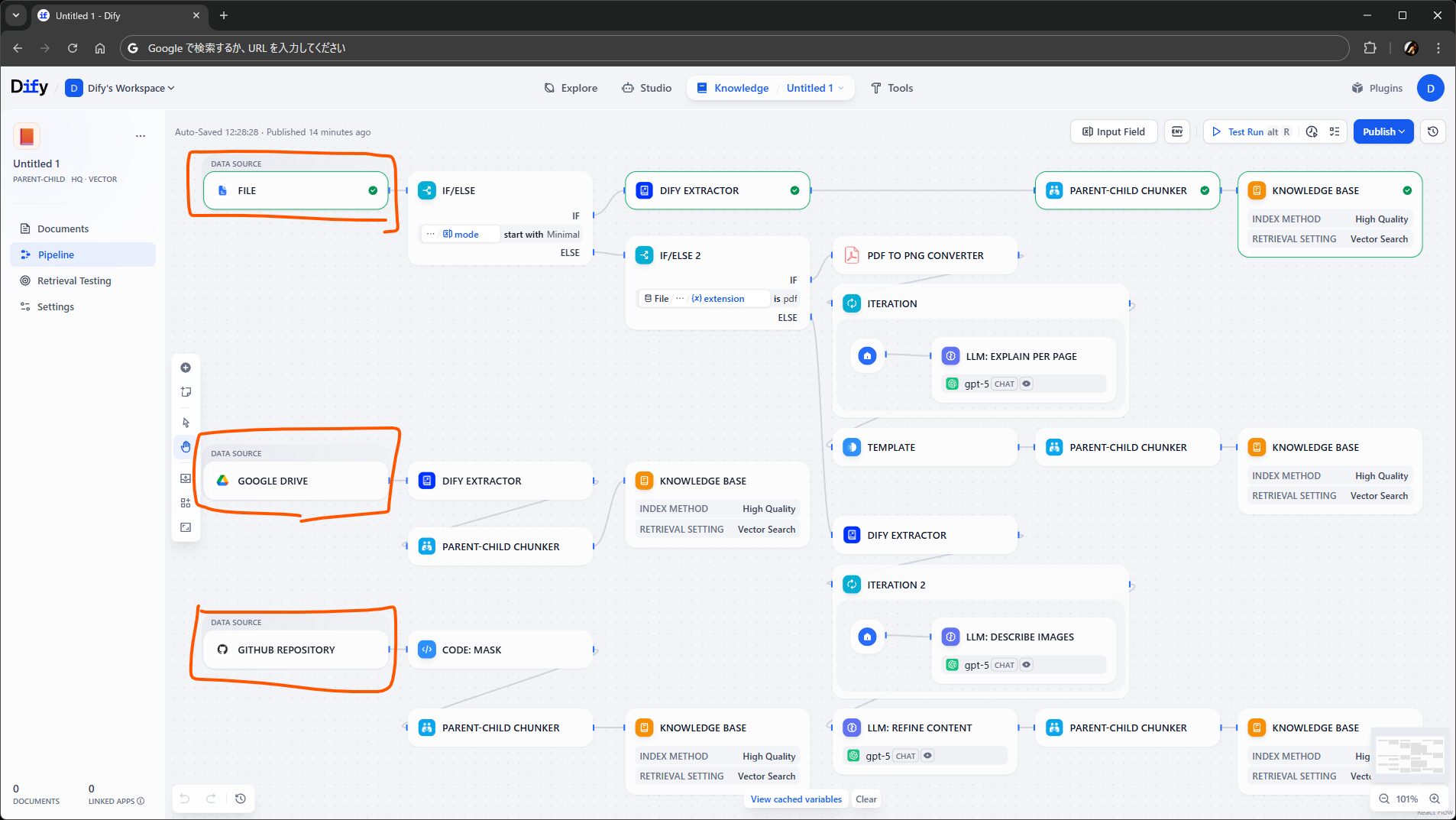
パイプライン上では、ワークフローでいう開始ノード相当 のものとして配置できます。ただし前述のとおり、ひとつのパイプラインに複数のデータソースノードを配置できます。
従来の Dify では、ナレッジの元ネタには手動アップロードか Notion か Web クローリングのいずれかしか選べませんでしたが、ナレッジパイプラインでは、データを取得する機能それ自体 が データソースプラグイン として提供されるため、プラグインをインストールすれば選択肢を増やせます。
ぼくが触っていた段階では、公式プラグイン としては以下が開発中でした(仕分けはぼくが勝手にしたものです)。今後も増えるでしょうし、パートナ企業さんやコミュニティからの公開も期待できるでしょう。なお、従来通りの 手動でのファイルのアップロード を受け付けるノードは、プラグインではなく標準でバンドルされています。
- オブジェクトストレージ系
- Amazon S3
- Azure Blob
- Google Cloud Storage
- オンラインストレージ系
- Box
- Dropbox
- Google Drive
- Microsoft OneDrive
- コラボレーションツール系
- Confluence
- GitLab
- GitHub
- Notion
- Microsoft SharePoint
- Web クローラー系
- Bright Data
- Firecrawl
- Jina Reader
- Tavily
これ以外だと、例えば SMB とか NFS とか、Teams とか Slack とか、そんなのにも需要が生まれそうです。
抽出・整形: 情報を抽出してクレンジングする
データソースから取得されたデータをもとに、ナレッジに登録する情報を作るステップです。
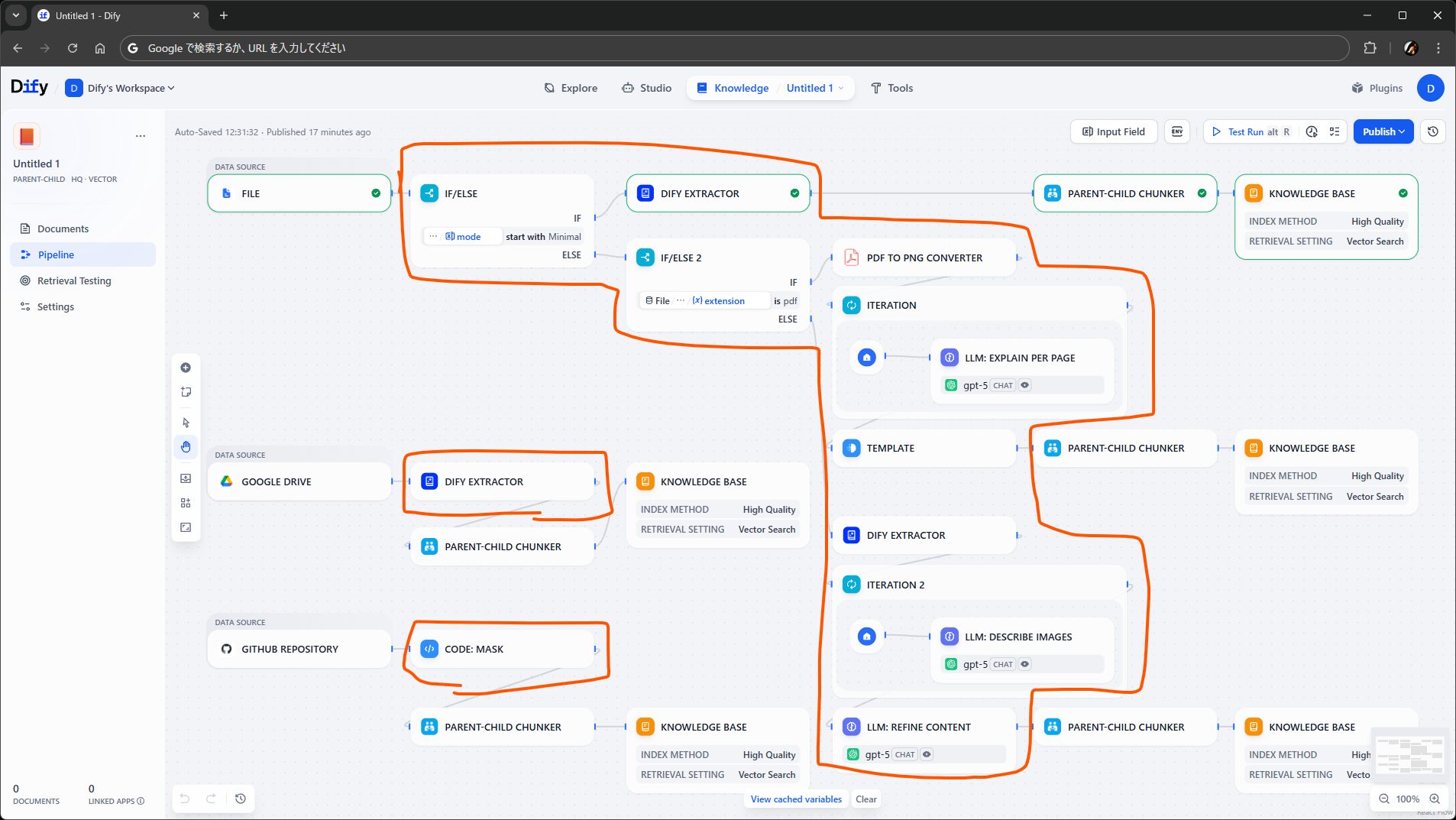
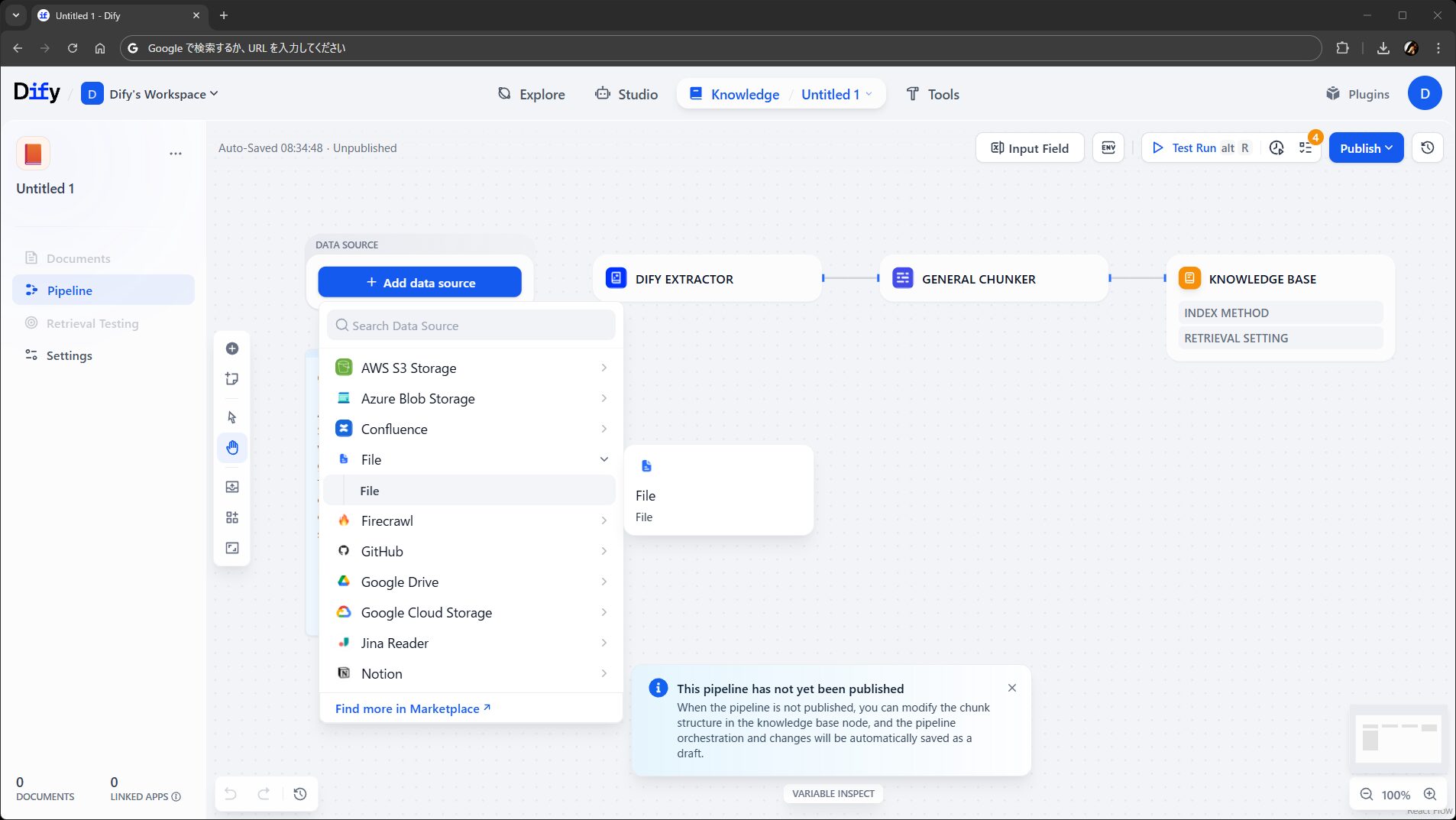
このステップ用に、従来のナレッジが持っていた機能のプラグイン版として、ファイルからテキストや画像を抽出する Dify Extractor、URL やメールアドレスを削除する Dify Cleaner が提供されています。最小限のパイプラインであれば、これらだけでも充分に機能します。
……が、パイプラインの価値 は、上の図のように、データに対する処理 を さまざまなノードやツールを駆使してワークフローっぽく自由に組める ところにあります(上の図は見た目重視で組んだだけのイメージですが)。
つまり、ステップ全体としては、
- 前段のステップからファイルオブジェクトまたはテキストや画像などのデータを受け取って
- 後段のステップにテキストデータとして渡す
ということさえできればよいので、ワークフローのように条件分岐やループを使ったり、LLM で要約や整形などの前処理をさせたり、コードブロックでキーワードの置換やマスクなど機械的な何かをしたりと、さまざまなノードやツールをパイプラインに組み込んで、必要なだけ整形なりクレンジングなりの作り込みができることになります。
チャンク: テキストをチャンク化する
前のステップから渡されたテキスト情報をチャンクに分けるステップです。
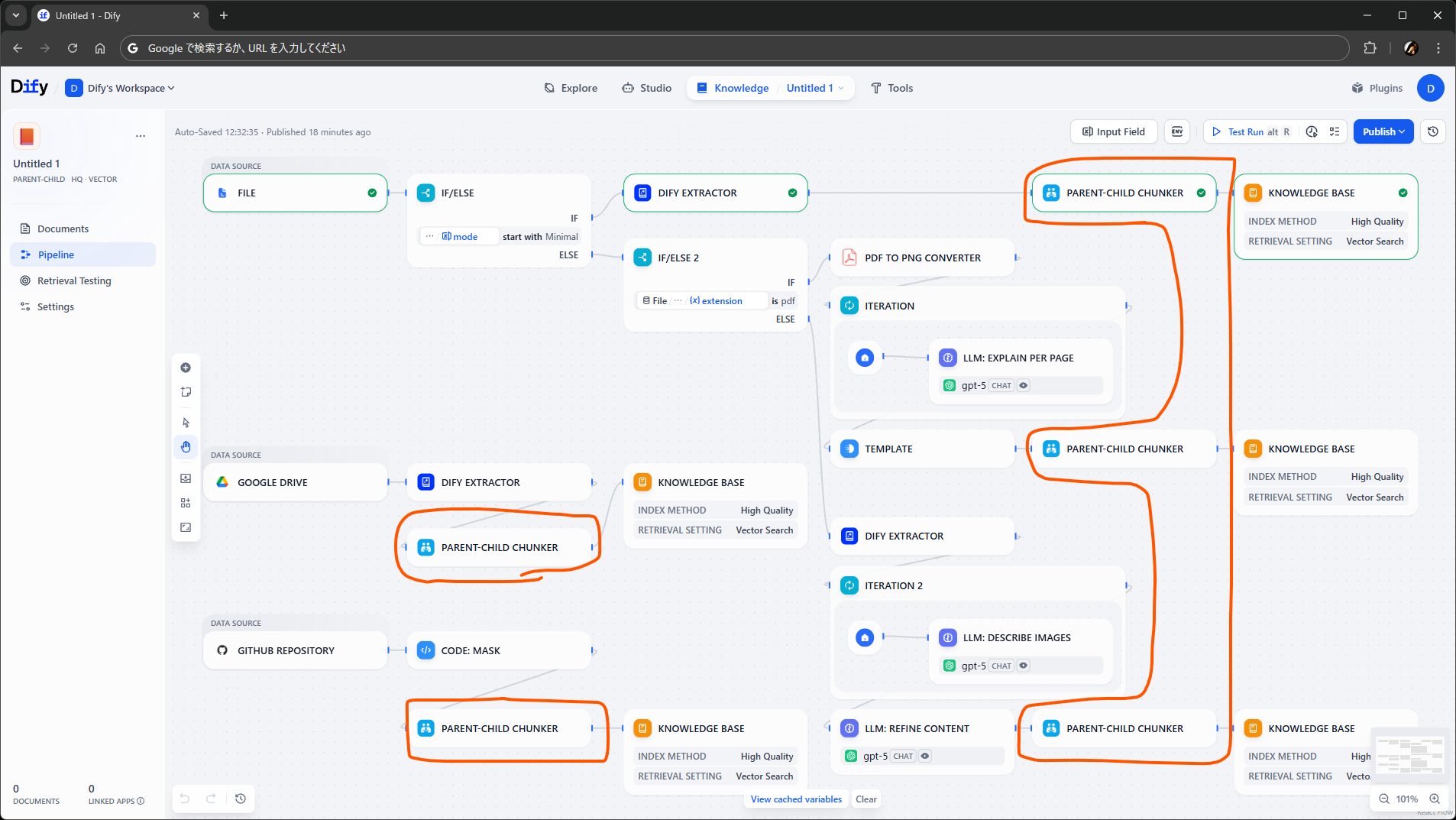
公式プラグインとして、次の三つが提供されていました。
- General Chunker(汎用チャンクを作成)
- Parent-child Chunker(親子チャンクを作成)
- Q&A Chunker(Q&A チャンクを作成)
汎用チャンクと親子チャンクは以前からあったものと同じです。ノードとして配置すると、前述のとおり、設定画面でチャンク長やデリミタなどを指定できるようになります。
Q&A チャンクは、質問と回答のペアをチャンク化したものです。従来のナレッジには LLM を使って Q&A 形式に整形させる選択肢がありましたが、Q&A Chunker はそれ ではなく、単に質問列と回答列を含む CSV ファイルを受け取って行ごとにチャンク化するだけのもののようです。
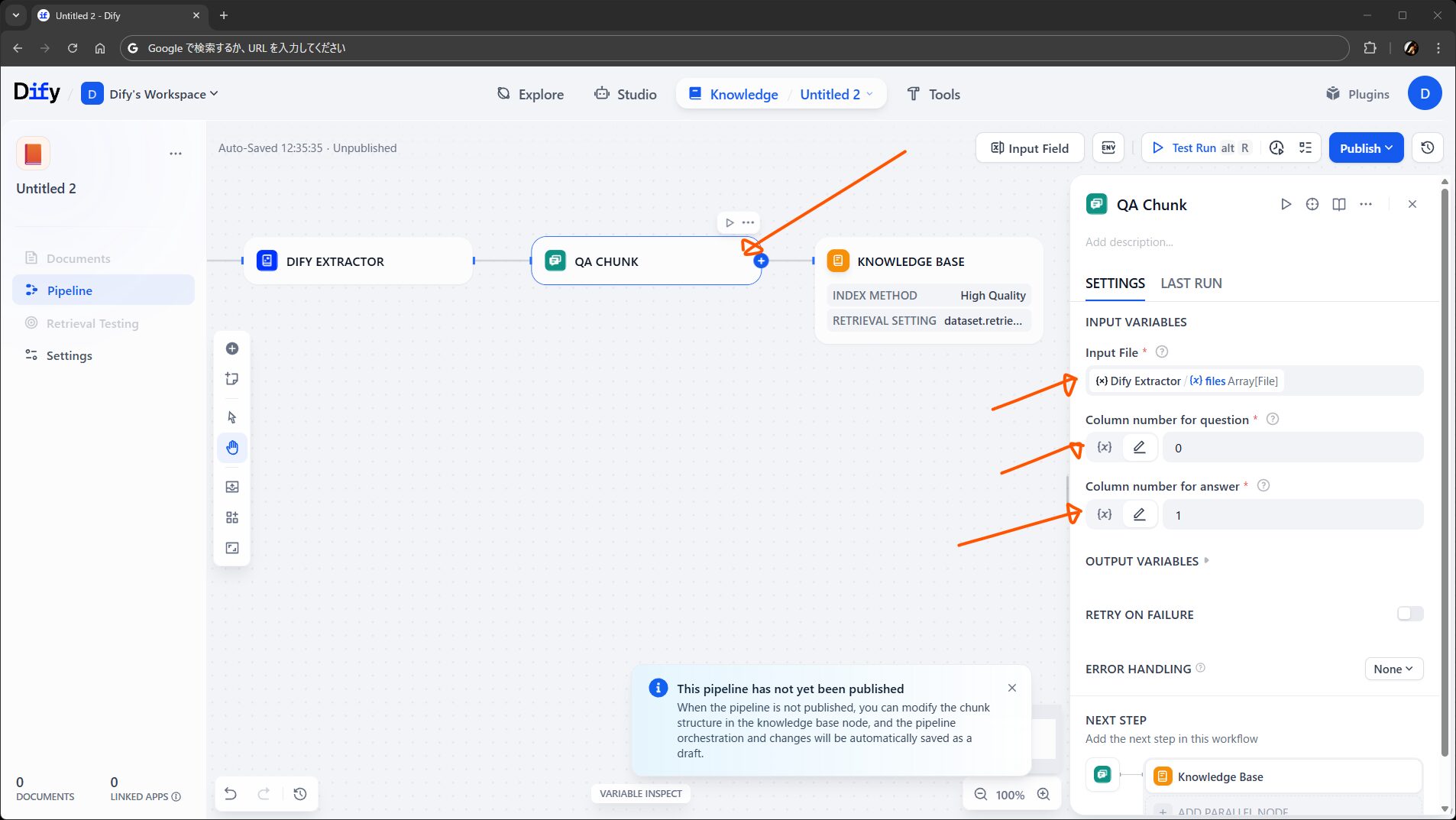
チャンクの種類自体は汎用・親子・Q&A の三種からは増やせませんが、例えば、特定の構造のテキストに特化したチャンキングを行えるプラグイン の実装なども考えられそうです。
ナレッジベース: チャンクを保存する
作成されたチャンクをナレッジに保存するステップです。
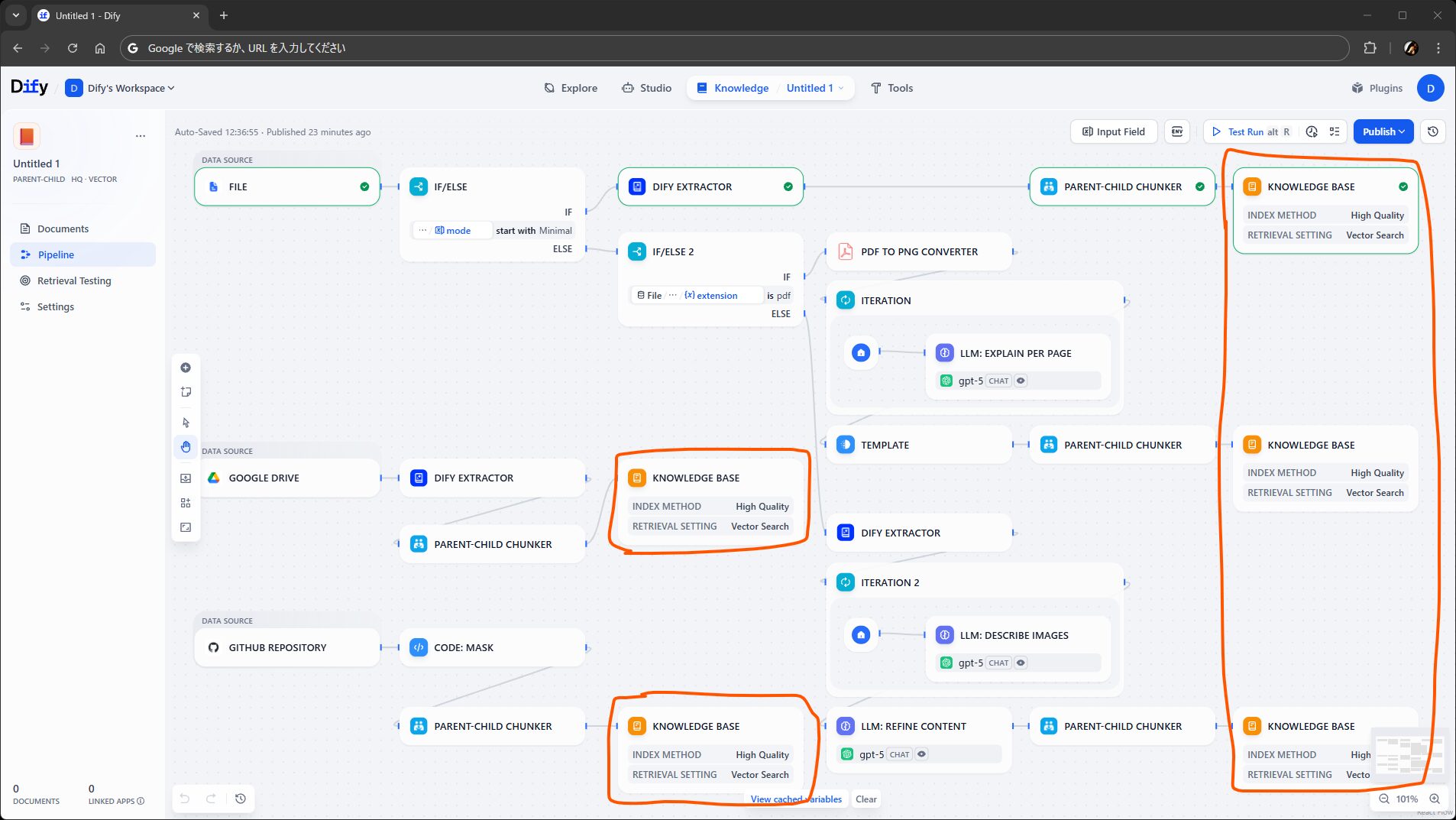
ここでは、前述のとおり、保存するチャンクを指定するほか、検索設定も行えます。Chunk Structure を選択すると、対応する型の変数が Input Variables で選べるようになります。
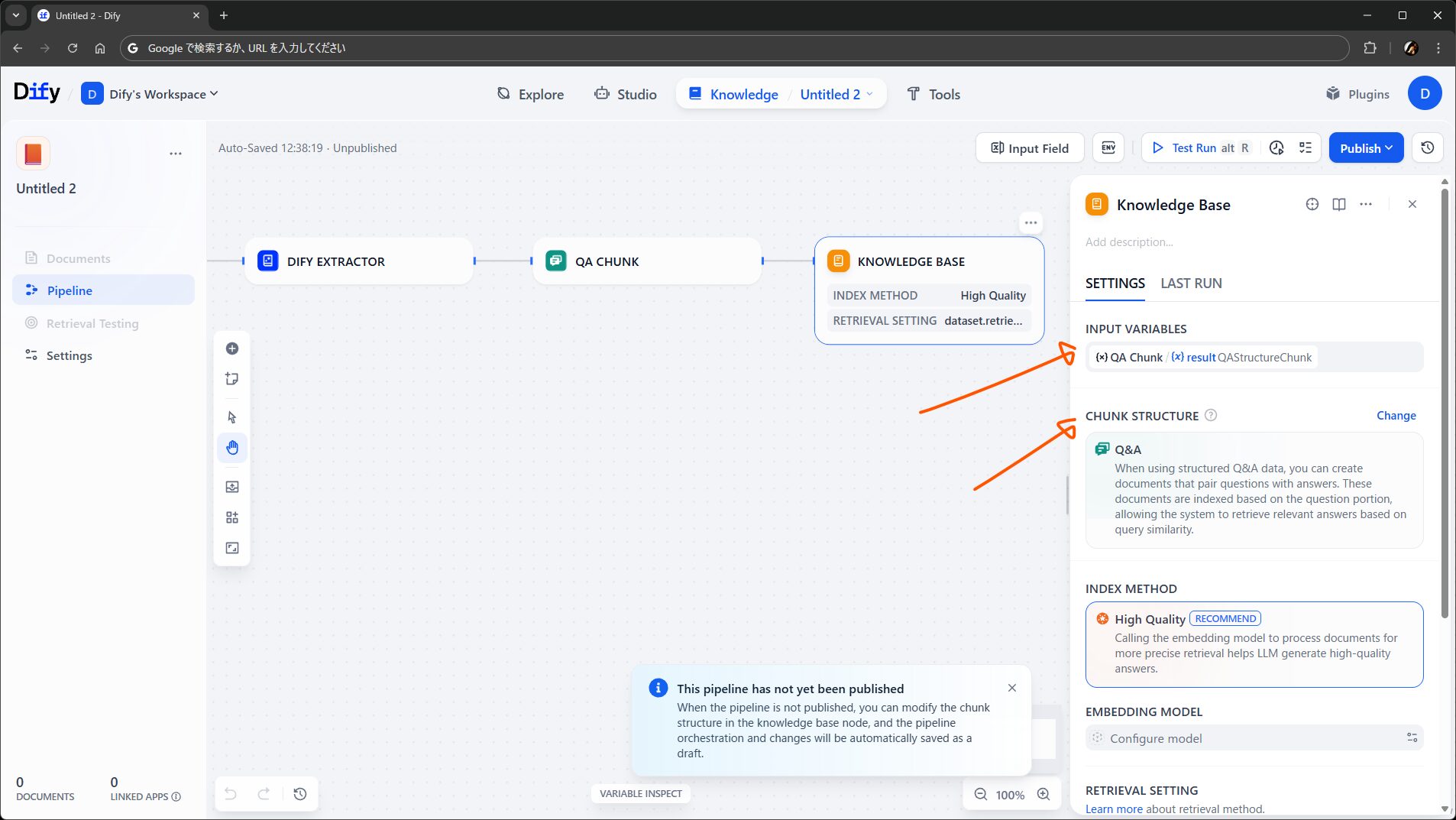
このノードは、パイプラインに必ずひとつ以上配置する必要があります。組み込みのノードであり、プラグインによる拡張はできません。
おわりに
ちょっと触っただけでも、これは一気にできることが増えたなあという気持ちにさせられる、大きいアップデートです。
特に、データソースがプラグインで拡張できること、抽出やクレンジングの処理を完全にコントロールできること、が大きな価値で、技術的には プラグインさえあれば(もしくは自分で作れば)、だいたいどこからでも何でも取ってこられる し、さらに どのようにでも加工して取り込める ようになったとも言えます。
一方で、以下のような点は今後の改善余地というか、運用上の注意を要する点というか、そういうのもありそうに思いました。
- ファイルの更新への追従
- 例えば、あるデータソース上のファイルやデータが、ナレッジに登録されたあとに更新されたとしても、Dify 側ではそれを検知できません
- ファイルの更新をナレッジに反映するには、人間が再度パイプラインをトリガする必要があります
- アプリにスケジュール機能が実装されたら、アプリからナレッジの API を定期的に叩いて同期させるようなこともできるかもしれませんが……
- ファイルの権限
- データソース側でデータやファイルのアクセス権を細かく設定していたとしても、それは Dify 側とは(当然ながら)連動せず、Dify に取り込まれた時点で Dify の制御下に置かれます
- ワークスペースの分離やナレッジのパーミッションに注意しないと、意図せずデータやファイルを参照されてしまう可能性もありそうです
- Enterprise 版で SSO を使っていて、かつデータソース側でも同じ ID が使われているのであれば、どうにかなってくれる…… とうれしいのですが、難易度は高そうな印象です
何はともあれ、夢のある機能でおもしろいですね。いろいろ触ってみましょう。触っていた段階ではバグも多かったのですが、直せそうな範囲でちょこちょこと修正のお手伝いもしていましたし、リリース時点(またはリリース後の早い段階)でもっと安定した状態になることに期待しています。
One thought to “RAG 2.0: Dify の新しいナレッジパイプラインを探る”