
マウスを買ったので写真を撮りました。というエントリです。
続きを読む月: 2020年2月
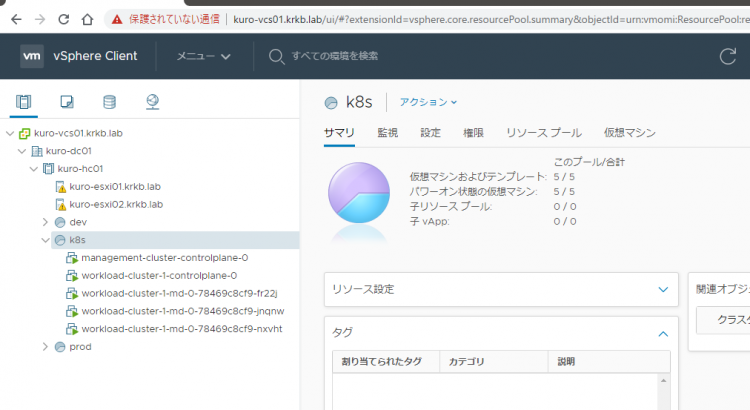
Cluster API で vSphere 上の Kubernetes クラスタを管理する
きっかけ
実験したいことが出てきてしまい、自宅で Kubernetes を触りたくなりました。
これまで Kubernetes を触る場合は Google Kubernetes Engine(GKE)ばかりを使っていたのですが、 今回実験したいのは IoT の世界でいうエッジ側の話なので、できればオンプレミス相当の Kuberentes クラスタが欲しいところです。
そんなわけで、これ幸いと自宅の vSphere 環境で Cluster API を叩いてゲストクラスタを作ることにしました。Cluster API は、2019 年に VMware から発表された VMware Tanzu や Project Pacific の実装でも使われているそうで、そういう意味でも興味のあるところです。
VMware Tanzu や Project Pacific は、エントリの本筋ではないので細かくは書きませんが、めっちゃ雑に書くと、vSphere と Kubernetes がイケてる感じにくっついたヤツです。
続きを読む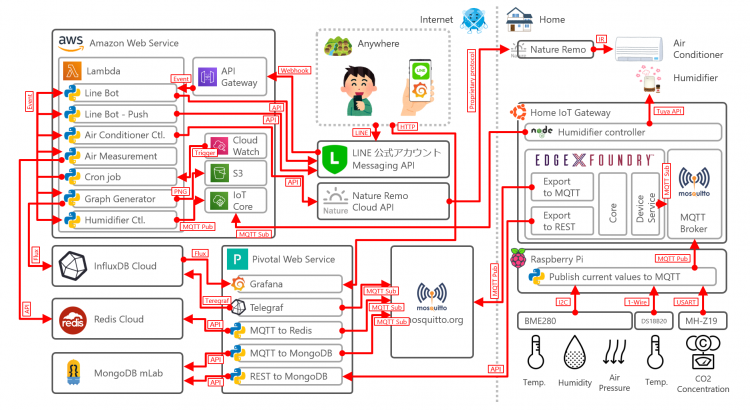
おうち IoT 用の LINE ボットをもう少し賢くする
これまでの LINE ボットの課題
2018 年に、家のエアコンを操作してくれる LINE ボットを作って以来、すでに一年半くらい運用しています。概要は 当時のエントリでも紹介しています が、LINE での会話を元に自宅のエアコンを操作してくれるものです。
これ、作った当初に想定していた以上にたいへん便利で、外出先で家族と『そろそろロボくんにお願いしておこう』などの会話が発生する程度には実際に活用されていました。この手の『作ってみた』系は、長期的な運用が定着する前に使わなくなることが多い印象もあり、これは小規模ではあるもののうまくいった例と言えるかと思います。
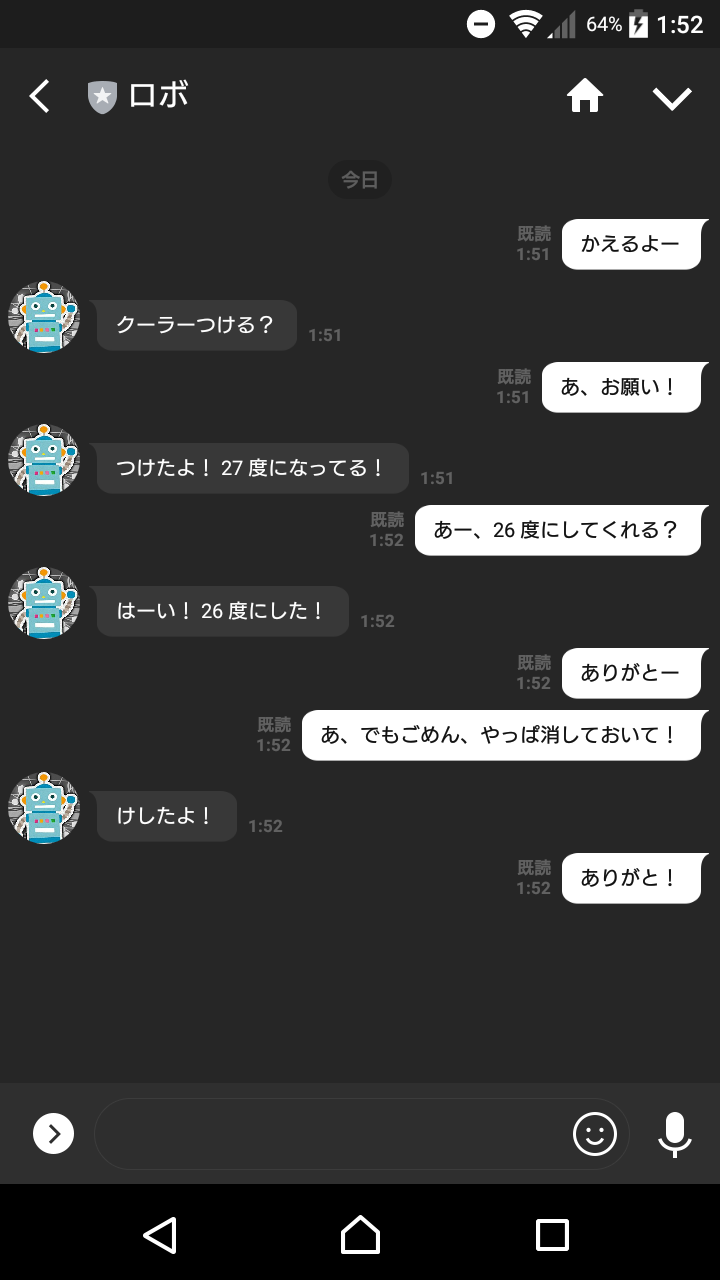
一方で、作りが甘い部分もあって、
- Lambda の Node.js のランタイムで EoL が迫っていた
- そもそも Node.js のランタイム側の更新に追従していくことに将来的にけっこう体力を使いそうな印象がある
- 当時 Node.js を選んだ理由は『とりあえずいちど触ってみたかった』からというだけで、すでにその目的は達成できた
- ひとつの Lambda に全機能を詰め込んでいて、どう考えてもイケてないアーキテクチャだ
- 機能が足りない
- エアコンのオンオフと温度の変更はできたが、冷房と暖房の切り替え機能を実装していない
など、長期的な運用に耐えられるよう全体を作り直したいモチベーションも強くなってきていました。
そんな中、あるイベントに参加して、『Raspberry Pi とセンサとクラウドサービスを使って何でもいいから個人で何かを作る』という活動をすることになり、タイミングもよかったので、この LINE ボットの作り直しを進めることにしました。
続きを読む